RTX4090有一个很奇特的特性,使用 fp16 accum 的 matmul 的吞吐量是使用 fp32 accum 的 matmul 的两倍。
这是非常诱人的加速!
起源
事情的起源是在 nvidia-ada-gpu-architecture 中看到 RTX4090 相关的数据
| Graphics Card | TFLOPS |
|---|---|
| Peak FP8 Tensor TFLOPS with FP16 Accumulate | 660.6 |
| Peak FP8 Tensor TFLOPS with FP32 Accumulate | 330.3 |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate | 330.3 |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate | 165.2 |
| Peak BF16 Tensor TFLOPS with FP32 Accumulate | 165.2 |
| Peak TF32 Tensor TFLOPS | 82.6 |
| Peak INT8 Tensor TOPS | 660.6 |
| Peak INT4 Tensor TOPS | 1321.2 |
对于 4090这样的消费级显卡(consumer cards),使用
fp16 accum 的 matmul 的吞吐量是使用 fp32 accum
的 matmul 的两倍。而 A100/H00 这样的数据中心显卡(data center
cards)则没有这种特性。
- 消费级显卡
是面向普通消费者设计的显卡,主要用于个人电脑,以满足游戏、多媒体处理等日常使用需求
- 数据中心显卡
是专为数据中心和企业级应用设计的显卡,主要用于大规模计算任务,如深度学习、数据分析和高性能计算这是非常诱人的加速!
于是计划做以下几部分:
- 验证加速效果
- 结合attention验证精度损失
- 集成到 vllm 进行加速
1. 性能验证实验
1.1 FP16 Tensor
实验使用cutlass代码(commit bdd641790ad49353b40ada41330552a78d2f8b5a)
指导文档 CUTLASS C++ Quick Start Guide
1 | mkdir build && cd build |
参照 profiler,执行测试
点击展开/折叠 测试代码
1 | 单独测试 |
写个小脚本跑测试 1
2
3
4
5
6
7
8
9!/bin/bash
start_size=256
end_size=16384
step_size=256
for size in $(seq $start_size $step_size $end_size); do
./tools/profiler/cutlass_profiler --kernels=gemm --op_class=tensorop --m=$size --n=$size --k=$size --accum=f16,f32 --A=f16:row --B=f16:column --D=f16:column --stages=3 --output=report/report_${size}.csv
done
记录相关Arguments
1 | Arguments: --gemm_kind=universal --m=4096 --n=4096 --k=4096 --A=f16:row --B=f16:column --C=f16:column --D=f16:column \ |
其中,可以发现
- accum = fp16用的 operator 是
cutlass_tensorop_h16816gemm_256x128_32x3_tn_align8 - accum = fp32用的 operator 是
cutlass_tensorop_f16_s16816gemm_f16_256x128_32x3_tn_align8
难怪二者能差一倍的性能,h16816gemm 用的 half
precision (FP16) 的 gemm, s16816gemm 用的是 single
precision (FP32) 的 gemm。
ncu 看一下
1 | ncu --target-processes all --set full --import-source yes -f -o ncu_log_ada_fp16_1024_f16acc ./tools/profiler/cutlass_profiler --kernels=gemm --op_class=tensorop --m=1024 --n=1024 --k=1024 --accum=f16 --A=f16:row --B=f16:column --D=f16:column --stages=3 |
试验结果:
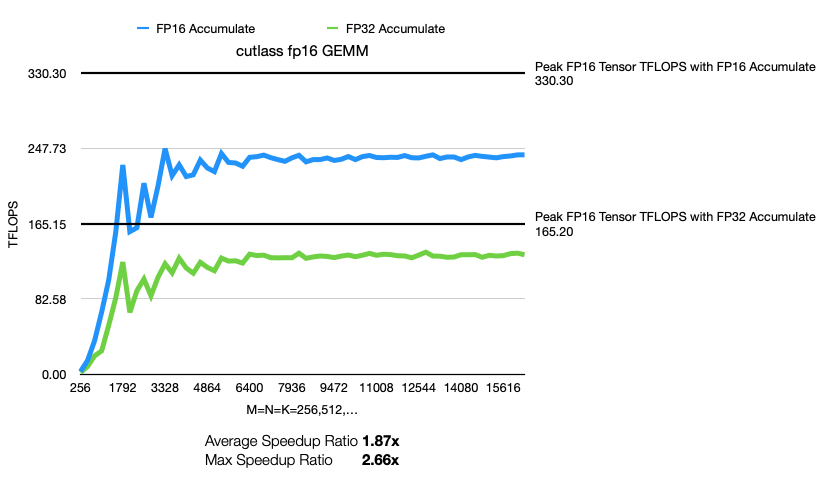
果然,加速效果非常明显!
1.2 FP8 Tensor
在cutlass工程里面单独编译
1 | cd cutlass/examples/58_ada_fp8_gemm/ |
我新建了一个项目,代码摘自cutlass/examples/58_ada_fp8_gemm,相关代码开源至github
1 | cd ada_fp8_gemm/ |
官方代码里分了 staged 和 fast 两种:
1 | TestbedRunner<Gemm_<cutlass::arch::OpMultiplyAdd>> testbed_staged_accum; |
这两种模式代表了精度与性能的权衡:
- OpMultiplyAdd: 精度优先,适合对数值稳定性要求高的场景
- 精度优势: 在 FP8 的有限精度下,分阶段计算可能更稳定
- OpMultiplyAddFastAccum: 性能优先,适合大规模高性能计算
- 速度优势: 充分利用 Tensor Core 的 FMA 指令
需要注意的是,cutlass::arch::OpMultiplyAddFastAccum,
which is only used for SM89 FP8 kernels.
细查一下代码,在代码的模版类中 1
2
3
4
5
6
7
8template <typename MathOperator>
using Gemm_ = cutlass::gemm::device::GemmUniversalWithAbsMax<
ElementA, LayoutA, ElementB, LayoutB, ElementOutput, LayoutC,
ElementAccumulator, cutlass::arch::OpClassTensorOp, cutlass::arch::Sm89,
cutlass::gemm::GemmShape<128, 64, 128>, cutlass::gemm::GemmShape<64, 32, 128>, cutlass::gemm::GemmShape<16, 8, 32>,
EpilogueOutputOp, cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle<>, kStages,
kAlignmentA, kAlignmentB, MathOperator
>;OpMultiplyAddFastAccum 和 OpMultiplyAdd
影响的是 MathOperator,给到
class GemmUniversalBase 的 Operator。
试验结果: 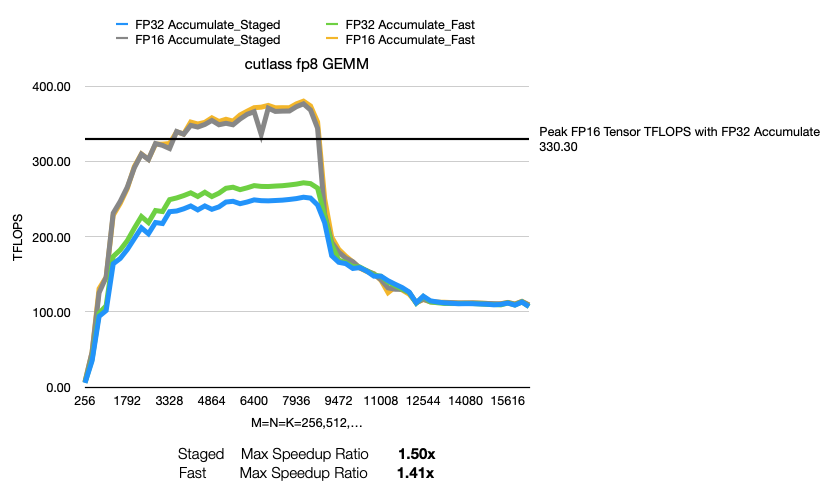
MNK尺寸比较大的时候有些异常,单独分析一下 1
2
3ncu --target-processes all --set full --import-source yes -f -o ncu_log_ada_fp8_4096 ./ada_fp8_gemm --m=4096 --n=4096 --k=4096 --iterations=1 --warmup-iterations=0 --reference-check=false
ncu --target-processes all --set full --import-source yes -f -o ncu_log_ada_fp8_14080 ./ada_fp8_gemm --m=14080 --n=14080 --k=14080 --iterations=1 --warmup-iterations=0 --reference-check=false
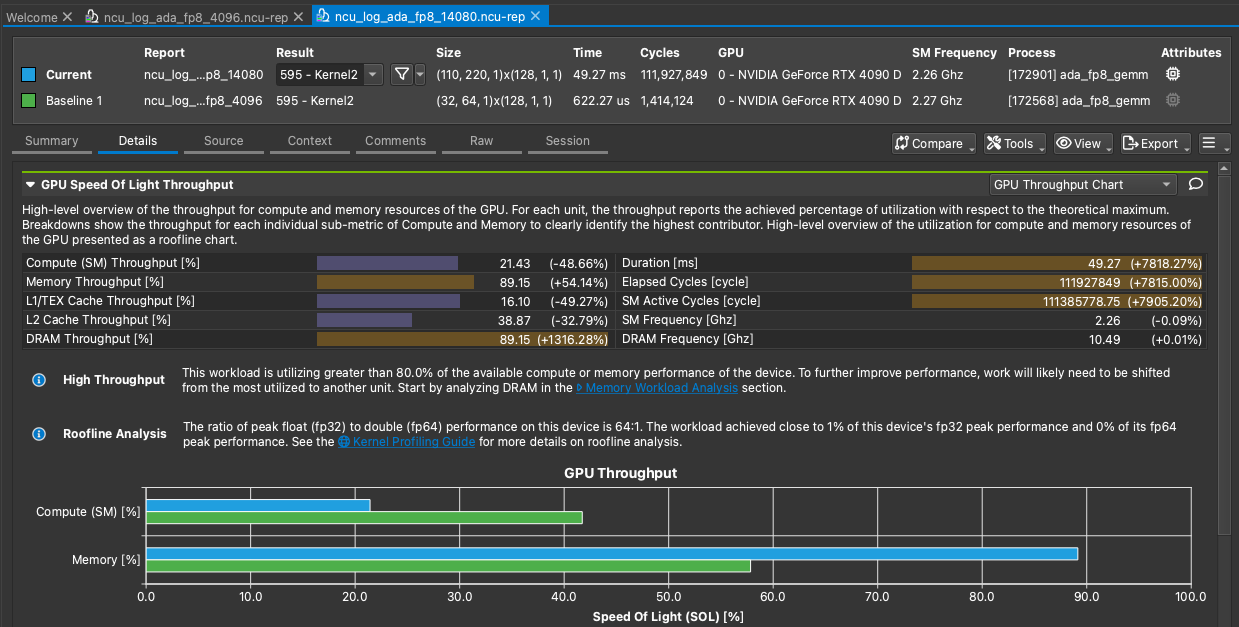
- M=N=k=4096的时候,Size = (32,64,1)x(128,1,1)
- M=N=k=8192的时候,Size = (64,128,1)x(128,1,1)
- M=N=k=14080的时候,Size = (110,220,1)x(128,1,1)
检查下来的结论是当使用 (110,220,1)x(128,1,1) kernel 的时候 L1/L2 cache Throughput 下降了很多,导致整体性能下降。
1.3 结论
对于 fp16 算子,使用 FP16 Accumulate 其实是使用了 half precision (FP16) 的 gemm,相比于使用 FP32的 gemm 确实是有极大的性能提升。
2.精度损失
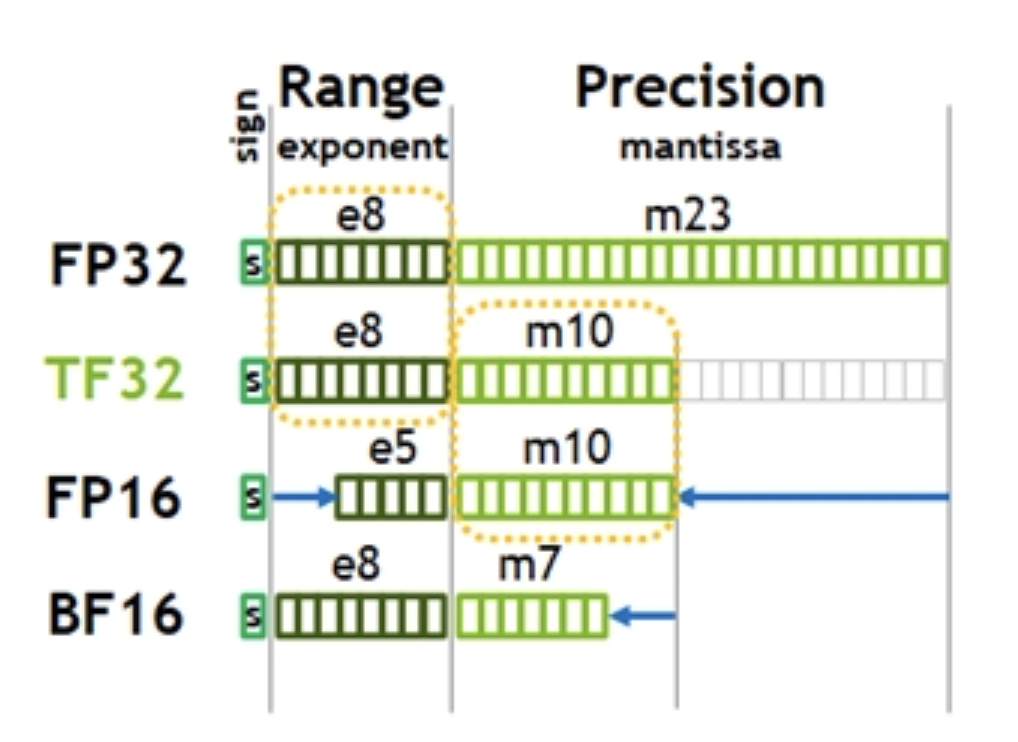
FP16(半精度浮点数)是一种16位浮点数格式,由以下三个部分组成:
- 1位符号位(S):表示数字的正负。
- 5位指数位(E):表示指数部分。
- 可以表示从0到31的整数。在FP16中,指数位采用偏移表示法,偏移量为15。因此,指数位的值减去15得到实际的指数。对于最大正数,指数位为31,实际指数为
31 - 15 = 16。
- 可以表示从0到31的整数。在FP16中,指数位采用偏移表示法,偏移量为15。因此,指数位的值减去15得到实际的指数。对于最大正数,指数位为31,实际指数为
- 10位尾数位(M):表示小数部分。
- 可以表示从0到1023的整数。在FP16中,尾数位表示的是二进制小数,即 1 + 尾数/1024。对于最大正数,尾数位为1023,表示的二进制小数为 \(1 + 1023/1024 = 1.9990234375\) 。 最大正数:当 E=30 且 M=1023 时,表示的值约为:65504
- \(1.9990234375 × 2^{16}\)。计算得到:\(1.9990234375×2^{16}=1.9990234375×65536=65504\)
也就是说,当gemm结果超过 65504 的话,就会出现饱和导致的精度问题。
这个很关键,一旦出现饱和就会造成inf,inf被存到kv cache后就别想有正确输出了。所以要及时的做 clamp。
2.1 相关讨论
相关讨论资料主要集中在2023年,学习一下:)
Ada GeForce (RTX 4090) FP8 cuBLASLt performance
- FP8计算只能达到额定吞吐量的一半,大约 330-340 TFLOPS
- 一种可能性是它可能与功率上限触发的时钟节流有关。
Fp8/fp16 accumulation on ada RTX 4090
To use FP8 kernels, the following set of requirements must be satisfied:
- All matrix pointers must be 16-byte aligned.
- A must be transposed and B non-transposed (The “TN” format).
- The compute type must be CUBLAS_COMPUTE_32F.
- The scale type must be CUDA_R_32F.
feat(pallas): Optimize Pallas Attention + Benchmark #17328
- FP16 accumulation for Q @ K matmul
- not committing due to questions on numerical stability
- However, performance gains (extra 20%) are very tempting
- FP16 accumulation for Q @ K matmul
perf: matmul accumulation does not need to default to float #543
- Accumulation is done in fp32 for numerical precision and numerical stability. Fp16 might get inf if e.g. Q @ K^T has entries larger than 65k.
- even Q @ K fp16 accumulation stability can be feasible with the right model choice.
- 由于 FlashAttention 中存在 softmax 缩放,会将每个块的输出缩放到可能非常小的程度
- Do you think it may be feasible to use fp16 accumulation for P @ V?
- We know that:
- Delayed softmax reciprocal (FA2): exp(k - amax) <= 1.0
- In-loop reciprocal (FA1): P is normalized to 1. In particular sum(P_j, axis=1) = 1 for all j
- We know that:
2.2 数据分布
跑一下 Qwen2.5-VL-7B-Instruct ,看了一下Vit attention的分布
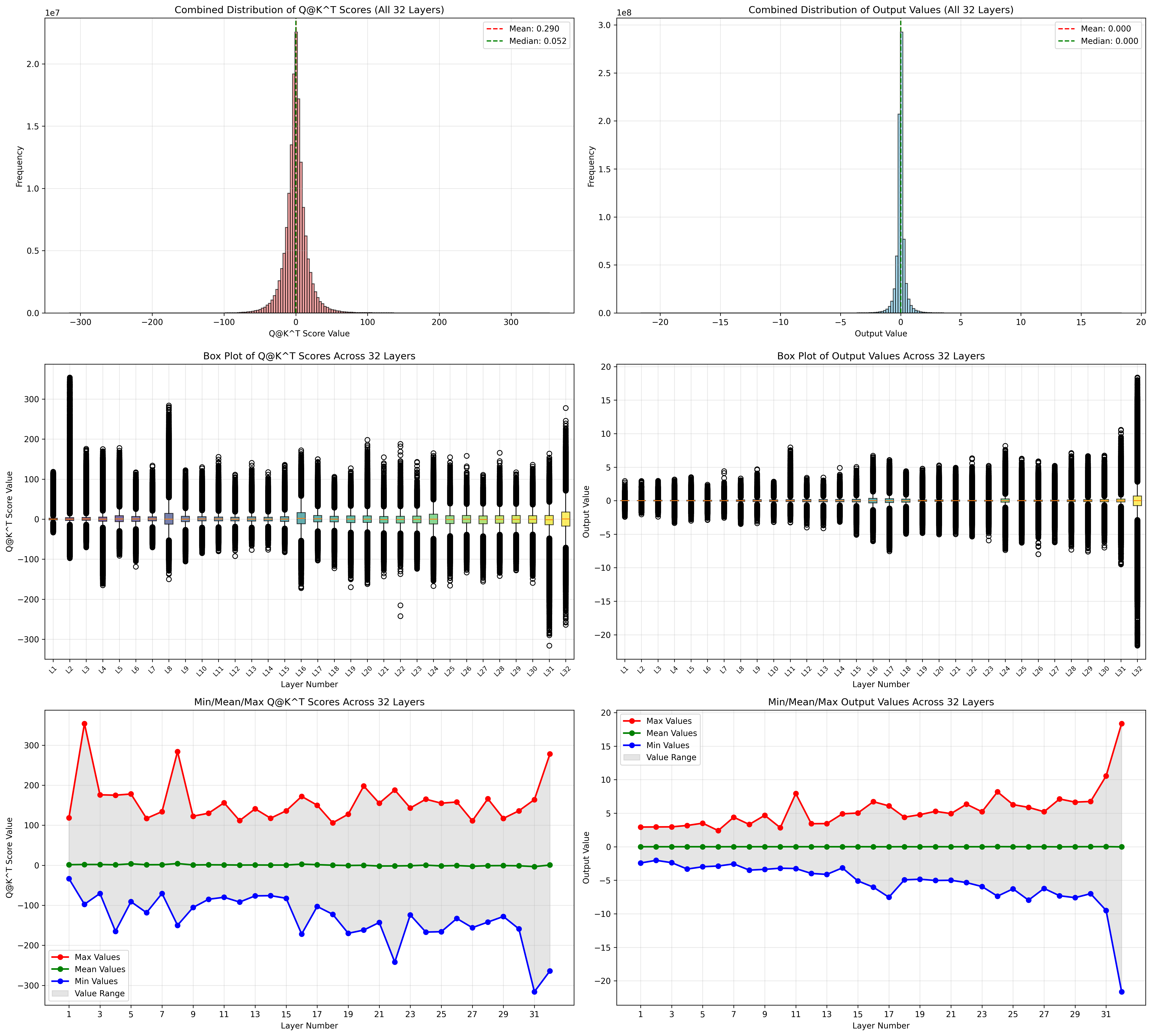
最大值没有超过 65505
language模型
prefill阶段
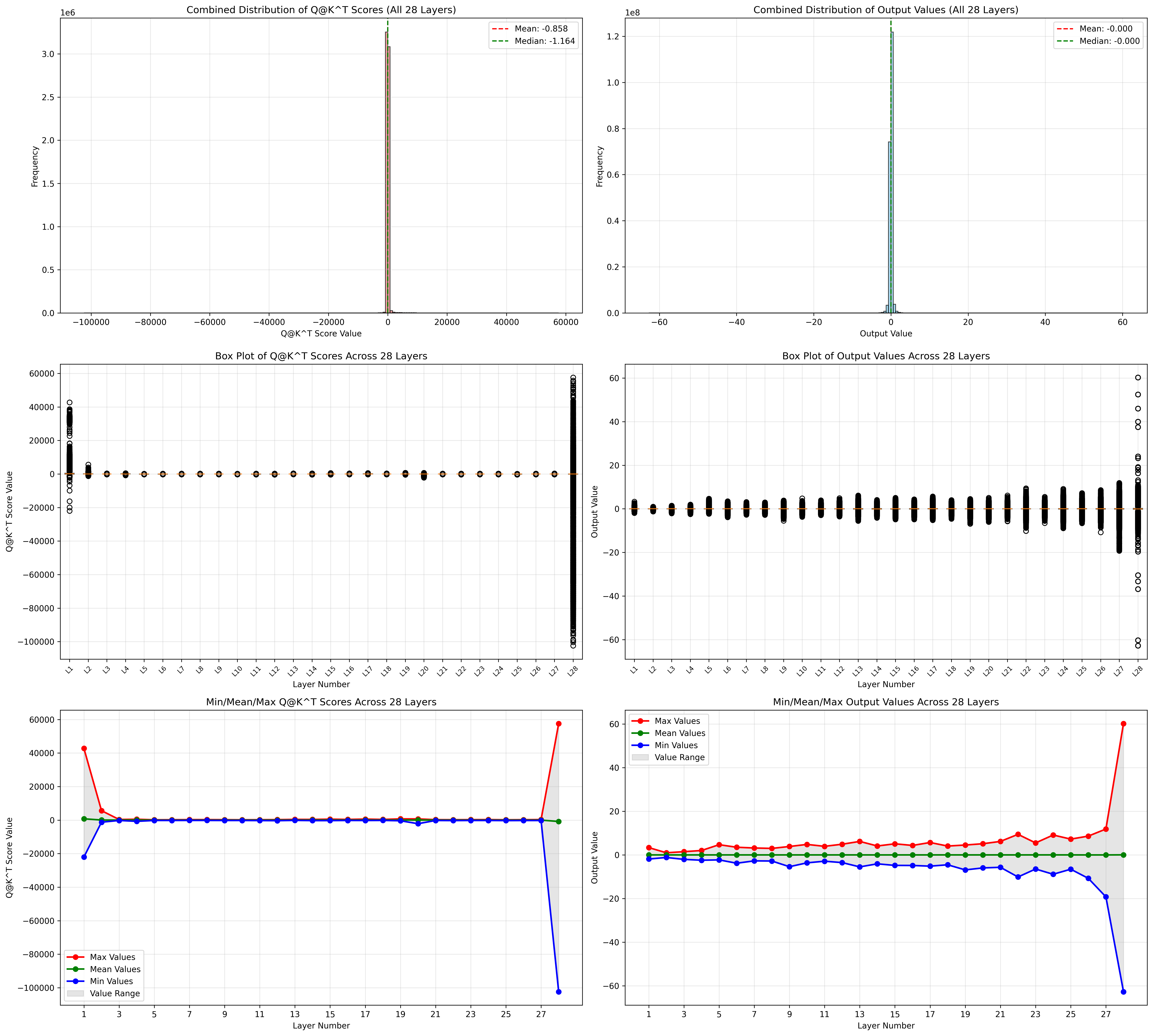
decode阶段
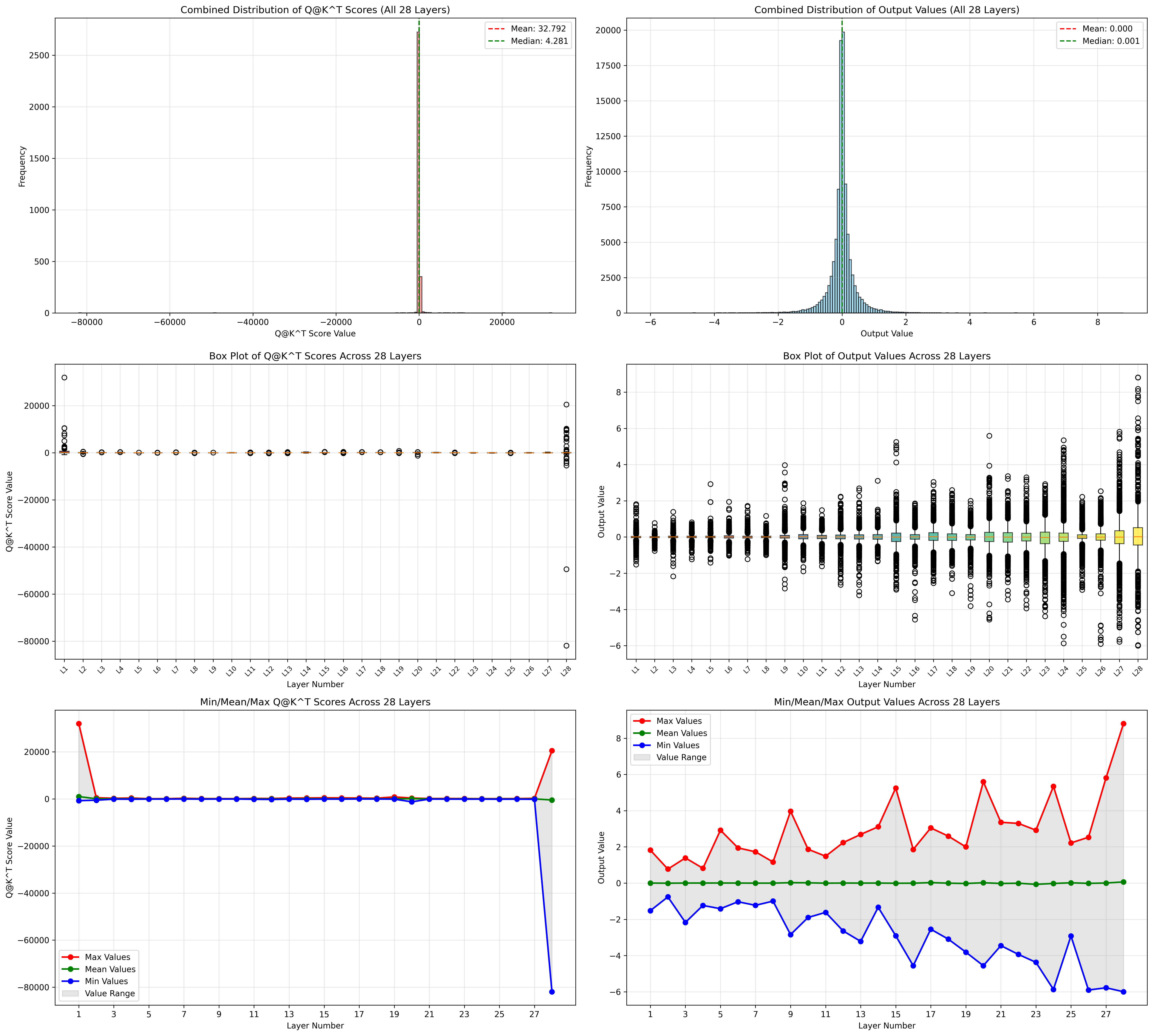
(更加详细的位于flash-attention-learning)
尤其注意第一层和最后一层的分布,尤其注意 Q@K^T 这个中间结果, 有超过 65505 的,这就意味着必须要有损了。
在vllm里面统计这个数据分布的代码位于v1/attention/backends/flash_attn.py
本来我还想,flash attention 是 tiling 的,是不是可以分担这个数据范围,后来一想,该 accum 的还是要 accum,没法避免。
3.算子修改
3.1 GEMM
在计算 将vllm里面涉及到fp16 gemm的计算改为自定义的 myop 算子(使用FP16 Accumulate)
涉及到vllm的compile,需要使用 direct_register_custom_op 进行注册,否则会报错
1 | /usr/local/lib/python3.12/dist-packages/torch/_dynamo/variables/functions.py:1262: UserWarning: Dynamo does not know how to trace the builtin `None.pybind11_object.__new__.` This function is either a Python builtin (e.g. _warnings.warn) or a third-party C/C++ Python extension (perhaps created with pybind). |
在vllm/vllm/utils.py中写到: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15"""
`torch.library.custom_op` can have significant overhead because it
needs to consider complicated dispatching logic. This function
directly registers a custom op and dispatches it to the CUDA backend.
See https://gist.github.com/youkaichao/ecbea9ec9fc79a45d2adce1784d7a9a5
for more details.
By default, the custom op is registered to the vLLM library. If you
want to register it to a different library, you can pass the library
object to the `target_lib` argument.
IMPORTANT: the lifetime of the operator is tied to the lifetime of the
library object. If you want to bind the operator to a different library,
make sure the library object is alive when the operator is used.
"""
其中提到的 https://gist.github.com/youkaichao/ecbea9ec9fc79a45d2adce1784d7a9a5 是很好的学习实践例子
1 | # 标准方式(有显著开销) |
torch.library.custom_op 需要考虑复杂的分发逻辑
- 支持多种设备后端(CPU、CUDA、ROCm、TPU等)
- 动态类型推断和验证
- 兼容性检查
direct_register_custom_op 如何优化?
- 直接分发到特定后端(通常是CUDA)
- 跳过复杂的分发逻辑
- 减少运行时开销
需要注意的点
1 | direct_register_custom_op( |
中的 mutates_args=["output_tensor"],那么在 myop_gemm_normal 函数中,一定要注意对 output_tensor 使用 in-place操作。
- 比如python中的 a = a + b 和 a += b
- a = a + b:创建新张量,不修改原数据,保留计算图,适用于需要梯度的场景。
- a += b:原地操作(in-place),可能破坏计算图,不保留梯度信息,适用于节省内存但不需要梯度的场景。
1 | from vllm.utils import direct_register_custom_op |
替换后性能暴涨,可行可行,继续加速fa!
3.2 Flash Attention
我是修改的vllm-project/flash-attention的相关代码
最关键的一行修改是
1 | diff --git a/csrc/flash_attn/src/kernel_traits.h b/csrc/flash_attn/src/kernel_traits.h |
即,将 MMA_Atom_Arch 修改为
SM80_16x8x16_F16F16F16F16_TN.
报错 1
2
3
4flash-attention/csrc/flash_attn/src/softmax.h(160): error: no operator "*=" matches these operands
operand types are: cutlass::half_t *= float
for (int ni = 0; ni < size<1>(acc_o_rowcol); ++ni) { acc_o_rowcol(mi, ni) *= scores_scale; }
^
1 | diff --git a/csrc/flash_attn/src/softmax.h b/csrc/flash_attn/src/softmax.h |
报错 1
2flash-attention/csrc/flash_attn/src/mask.h(184): note #3328-D: built-in operator-=(<arithmetic>, <promoted arithmetic>) does not match because argument #1 does not match parameter
tensor(make_coord(i, mi), make_coord(j, nj)) -= alibi_slope * abs(row_idx + max_seqlen_k - max_seqlen_q - col_idx);
解决方案 1
2
3
4
5
6
7
8
9
10
11
12
13diff --git a/CMakeLists.txt b/CMakeLists.txt
index e4423ef..d17505e 100644
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -166,7 +166,7 @@ if (FA2_ENABLED)
target_compile_definitions(_vllm_fa2_C PRIVATE
FLASHATTENTION_DISABLE_BACKWARD
FLASHATTENTION_DISABLE_DROPOUT
- # FLASHATTENTION_DISABLE_ALIBI
+ FLASHATTENTION_DISABLE_ALIBI
# FLASHATTENTION_DISABLE_SOFTCAP
FLASHATTENTION_DISABLE_UNEVEN_K
# FLASHATTENTION_DISABLE_LOCAL
为了防止出现 inf 导致模型输出全是感叹号,还要加一个防护:
1 | diff --git a/csrc/flash_attn/src/flash_fwd_kernel.h b/csrc/flash_attn/src/flash_fwd_kernel.h |
4.结果
4.1 FA Benchmark
在4090上单独跑了一下 fa ,几乎翻倍的效果,非常不错!
| Accumulate | headdim | causal | seqlen | TFLOPS | |
|---|---|---|---|---|---|
| Fav2 | FP32 | 128 | False | 8192 | 137.9 |
| Fav3 | FP32 | 128 | False | 8192 | 142.2 |
| Fav3 | FP16 | 128 | False | 8192 | 261.4 |
| Fav2 | FP32 | 128 | True | 8192 | 136.2 |
| Fav3 | FP32 | 128 | True | 8192 | 144.9 |
| Fav3 | FP16 | 128 | True | 8192 | 254.6 |
4.2 Qwen2.5 Speedup
pic size = 1920x1080
backend = Fav2
| DataType | 速度 | others | |
|---|---|---|---|
| baseline | bf16 | 3.06s/张 | transformer版本 |
| v1 | bf16 | 2.06s/张 | 使用vllm 单并发 |
| v2 | bf16 | 0.910s/张 | 使用vllm 异步多并发 |
| v3 | fp16 | 0.904s/张 | 使用vllm 异步多并发 |
| v4 | fp16 | 0.788s/张 | v3基础上加入myop加速gemm gemm使用FP16 Accumulate |
| v5 | fp16 | 0.600s/张 | v4基础上加入定制fa2 fa2使用FP16 Accumulate |
| v6 | fp16 | 0.500s/张 | v5基础上更换图像文本顺序 强化prefix caching |
总结
二者能差一倍的性能的原因在于,
h16816gemm用的 half precision (FP16) 的 gemm,s16816gemm用的是 single precision (FP32) 的 gemm。使用 FP16 Accumulate 其实是使用了 half precision (FP16) 的 gemm,相比于使用 FP32的 gemm 确实是有极大的性能提升,尤其是 fp16 算子。
需要注意溢出clamp,否则结果就传染脏了
加速效果不错,但确实略有损,初步评估可以接受,但需要进一步评估。
最终给他们两年前的讨论一个回复。


