今天Deepseek开源 FlashMLA,之前看过一些 MLA 相关知识了,感觉这是一个很好的学习 Cuda 加速的机会,于是实践学习记录一下。
0.准备工作
0.1 实验平台
如FlashMLA所讲:
FlashMLA is an efficient MLA decoding kernel for Hopper GPUs, optimized for variable-length sequences serving.
所以实验平台选择 Hopper 架构的 GPU。
实验平台信息
1 | Mon Feb 24 13:56:23 2025 |
0.2 安装
git clone https://github.com/deepseek-ai/FlashMLA.git
git submodule update --init csrc/cutlass/
python setup.py install
安装过程log
1 | # python setup.py install |
0.3 测试结果
- b:batch size(批大小)。
- s_q:query 序列长度。
- mean_sk:每个 batch 平均 key 长度。
- h_q:query 头数(head 数)。
- h_kv:key-value 头数。
- d:head 维度(查询、键的维度)。
- dv:value 维度。
- causal:是否启用因果掩码(Causal Masking)。
- varlen:是否使用可变序列长度。
| b | s_q | mean_sk | h_q | h_kv | d | dv | Causal | Varlen | TFLOPS | GB/s |
|---|---|---|---|---|---|---|---|---|---|---|
| 128 | 1 | 4096 | 16 | 1 | 576 | 512 | True | False | 0.609 | 998 |
| 128 | 1 | 4096 | 16 | 1 | 576 | 512 | True | True | 0.634 | 965 |
| 128 | 2 | 4096 | 16 | 1 | 576 | 512 | True | False | 0.610 | 1004 |
| 128 | 2 | 4096 | 16 | 1 | 576 | 512 | True | True | 0.634 | 1001 |
| 128 | 1 | 4096 | 32 | 1 | 576 | 512 | True | False | 0.613 | 1000 |
| 128 | 1 | 4096 | 32 | 1 | 576 | 512 | True | True | 0.645 | 998 |
| 128 | 2 | 4096 | 32 | 1 | 576 | 512 | True | False | 0.618 | 1005 |
| 128 | 2 | 4096 | 32 | 1 | 576 | 512 | True | True | 0.622 | 995 |
| 128 | 1 | 4096 | 64 | 1 | 576 | 512 | True | False | 0.621 | 1002 |
| 128 | 1 | 4096 | 64 | 1 | 576 | 512 | True | True | 0.631 | 965 |
| 128 | 2 | 4096 | 64 | 1 | 576 | 512 | True | False | 1.186 | 539 |
| 128 | 2 | 4096 | 64 | 1 | 576 | 512 | True | True | 1.261 | 528 |
| 128 | 1 | 4096 | 128 | 1 | 576 | 512 | True | False | 1.191 | 537 |
| 128 | 1 | 4096 | 128 | 1 | 576 | 512 | True | True | 1.235 | 523 |
| 128 | 2 | 4096 | 128 | 1 | 576 | 512 | True | False | 2.394 | 282 |
| 128 | 2 | 4096 | 128 | 1 | 576 | 512 | True | True | 2.516 | 276 |
| 128 | 1 | 8192 | 16 | 1 | 576 | 512 | True | False | 1.175 | 1032 |
| 128 | 1 | 8192 | 16 | 1 | 576 | 512 | True | True | 1.198 | 1012 |
| 128 | 2 | 8192 | 16 | 1 | 576 | 512 | True | False | 1.173 | 1037 |
| 128 | 2 | 8192 | 16 | 1 | 576 | 512 | True | True | 1.271 | 1024 |
| 128 | 1 | 8192 | 32 | 1 | 576 | 512 | True | False | 1.178 | 1033 |
| 128 | 1 | 8192 | 32 | 1 | 576 | 512 | True | True | 1.147 | 1012 |
| 128 | 2 | 8192 | 32 | 1 | 576 | 512 | True | False | 1.183 | 1036 |
| 128 | 2 | 8192 | 32 | 1 | 576 | 512 | True | True | 1.151 | 1017 |
| 128 | 1 | 8192 | 64 | 1 | 576 | 512 | True | False | 1.190 | 1030 |
| 128 | 1 | 8192 | 64 | 1 | 576 | 512 | True | True | 1.162 | 1011 |
| 128 | 2 | 8192 | 64 | 1 | 576 | 512 | True | False | 2.305 | 539 |
| 128 | 2 | 8192 | 64 | 1 | 576 | 512 | True | True | 2.408 | 532 |
| 128 | 1 | 8192 | 128 | 1 | 576 | 512 | True | False | 2.314 | 537 |
| 128 | 1 | 8192 | 128 | 1 | 576 | 512 | True | True | 2.508 | 529 |
| 128 | 2 | 8192 | 128 | 1 | 576 | 512 | True | False | 4.698 | 272 |
| 128 | 2 | 8192 | 128 | 1 | 576 | 512 | True | True | 4.648 | 270 |
测试结果log
1 | # python tests/test_flash_mla.py |
1.学习分析
接下来开始学习分析源码,本文以下面的配置为例:
- b = 128
- s = 4096
- h_q = 32 (TP=4)
- s_q = 1 (MTP = 1)
- varlen = False
进入tests/test_flash_mla.py 的
test_flash_mla() 函数。
1 | cache_seqlens = torch.full((b,), mean_sk, dtype=torch.int32) # 初始化一个长度为 b 的张量,每个 batch 样本的 key-value 序列长度均设为 mean_sk。 |
从 key 张量中取前 dv 维作为 value,避免额外分配新的 blocked_v 张量,提高内存效率,提高数据局部性。
在注意力计算中,key (K) 的维度 d 可能比 value (V) 的维度 dv 更大:
- K 主要用于计算注意力权重(与 query (Q) 进行 softmax(QK^T) 计算)。
- V 仅用于加权求和,所以 dv 可以小于 d,减少计算量。
在目前的例子中,
- blocked_k 维度 [8192, 64, 1, 576]
- blocked_v 维度 [8192, 64, 1, 512]
其中,8192 = 128(batch) * 4096(max_seqlen_pad) // 64(block_size), 64 为 block_size
要实现的是如下计算:

图中 V 和 K 中的一部分是浅绿色,表示这部分共享相同的数据。将
QK=P 定义为gemm 1,PV=O
定义为gemm 2。本图参考了LingYe.
1.1 基础实现 ref_mla
先看一下基础的 pytorch 的实现,已经熟悉 attention 计算的可以直接跳过这部分~
ref_mla 要实现的就是
$ Attention(Q,K,V) = softmax() V $
1 | def ref_mla(): |
out 维度 [b, s_q, h_q, dv]
lse 维度 [b, h_q, s_q]
只看一个batch
1 | q[i].transpose(0, 1).shape = torch.Size([32, 1, 576]) |
接下来看 scaled_dot_product_attention 函数
1 | def scaled_dot_product_attention(query, key, value, h_q, h_kv, is_causal=False): |
其中,
attn_weight = query @ key.transpose(-2, -1) / math.sqrt(query.size(-1))
实现的是计算注意力权重
点积注意力计算公式:
\[\text{attn\_weight} = \frac{QK^T}{\sqrt{d_k}}\]
其中 \(d_k\) 是
query的最后一维大小,用于 缩放(Scaling) 以防梯度爆炸。
1.2 主角登场 flash_mla
开始步入正题!
整体来看,flash_mla 包含两个函数:
- get_mla_metadata
- 负责 token 级别负载均衡
- 计算
tile_scheduler_metadata和num_splits信息,用于后续高效计算
- flash_mla_with_kvcache
- 负责paged attention计算
1.2.1 负载均衡
get_mla_metadata
一个 batch 里面有很多 seq, 每个 seq 的 len 都不一样,如果启动 kernel 的时候 grid size 设置成 batch size计算就不均衡,所以先算出 seq 的总长然后按照 sm 数量进行均匀的分配。这样就有句子会切断,
get_mla_metadata就记录这些分割点的信息。这些是所有flashxxx的通用做法。 来源:刘俊是
1 | tile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv) |
输入:
- cache_seqlens
- 即 batch_size 本文中是 torch.Size([128])
- s_q * h_q // h_kv
- num_heads_per_head_k = 1 * 32 // 1
- h_kv
- num_heads_k = 1
输出:
- tile_scheduler_metadata
- (num_sm_parts, TileSchedulerMetaDataSize = 8)
- torch.Size([78, 8])
- num_splits
- batch_size + 1
- orch.Size([129])
- 记录第batch_id 的batch在k seqlen 被拆分了几个thread block
这个函数的实现位于 flash_api.cpp ,计算元数据用于GPU加速推理和计算,为 num_heads_k 个头部划分 SM 资源,确保计算负载均衡。
1 | num_sm_parts = sm_count / num_heads_k / cutlass::ceil_div(num_heads_per_head_k, block_size_m); |
num_sm_parts为在k seqlen 维度并行的thread
block数目(类似flash decoding),撑满 wave 的并行度,提高GPU的利用率。
--from CalebDu
具体计算在 csrc/flash_fwd_mla_kernel.h 的
get_mla_metadata_func函数的
get_mla_metadata_kernel.
要注意的是, tile_scheduler_metadata
的其中一个维度虽然是
TileSchedulerMetaDataSize = 8,但是只用到了其中的5个,设置为8是为了
int4(16B) 对齐。
这5个分别是:每个sm要处理的起始seq idx,起始seq的token idx, 结束seq idx, 结束seq的token idx, 起始的seq是否被分割了。
1 | tile_scheduler_metadata0[0] = now_idx; |
打印 tile_scheduler_metadata 看一下:
| sm | begin_idx | begin_seqlen | end_idx | end_seqlen | n_split_idx | unused | unused | unused |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 2880 | 0 | 0 | 0 | 0 |
| 1 | 1 | 2880 | 3 | 1344 | 1 | 0 | 0 | 0 |
| 2 | 3 | 1344 | 4 | 4096 | 1 | 0 | 0 | 0 |
| 3 | 5 | 0 | 6 | 2880 | 0 | 0 | 0 | 0 |
| 4 | 6 | 2880 | 8 | 1344 | 1 | 0 | 0 | 0 |
| 5 | 8 | 1344 | 9 | 4096 | 1 | 0 | 0 | 0 |
| 6 | 10 | 0 | 11 | 2880 | 0 | 0 | 0 | 0 |
| 7 | 11 | 2880 | 13 | 1344 | 1 | 0 | 0 | 0 |
| 8 | 13 | 1344 | 14 | 4096 | 1 | 0 | 0 | 0 |
| 9 | 15 | 0 | 16 | 2880 | 0 | 0 | 0 | 0 |
| 10 | 16 | 2880 | 18 | 1344 | 1 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | 0 | 0 | 0 |
| 74 | 123 | 1344 | 124 | 4096 | 1 | 0 | 0 | 0 |
| 75 | 125 | 0 | 126 | 2880 | 0 | 0 | 0 | 0 |
| 76 | 126 | 2880 | 127 | 4096 | 1 | 0 | 0 | 0 |
| 77 | 128 | 0 | 127 | 4096 | 0 | 0 | 0 | 0 |
可以看到metadata记录了每个thread block的开始和结束信息。这里有点像之前看的 Marlin gemm 算子的 streamK 的思想,进行了任务的分割,实现不同 patch 的 k seqlen 并行的thread block之间的负载均衡。
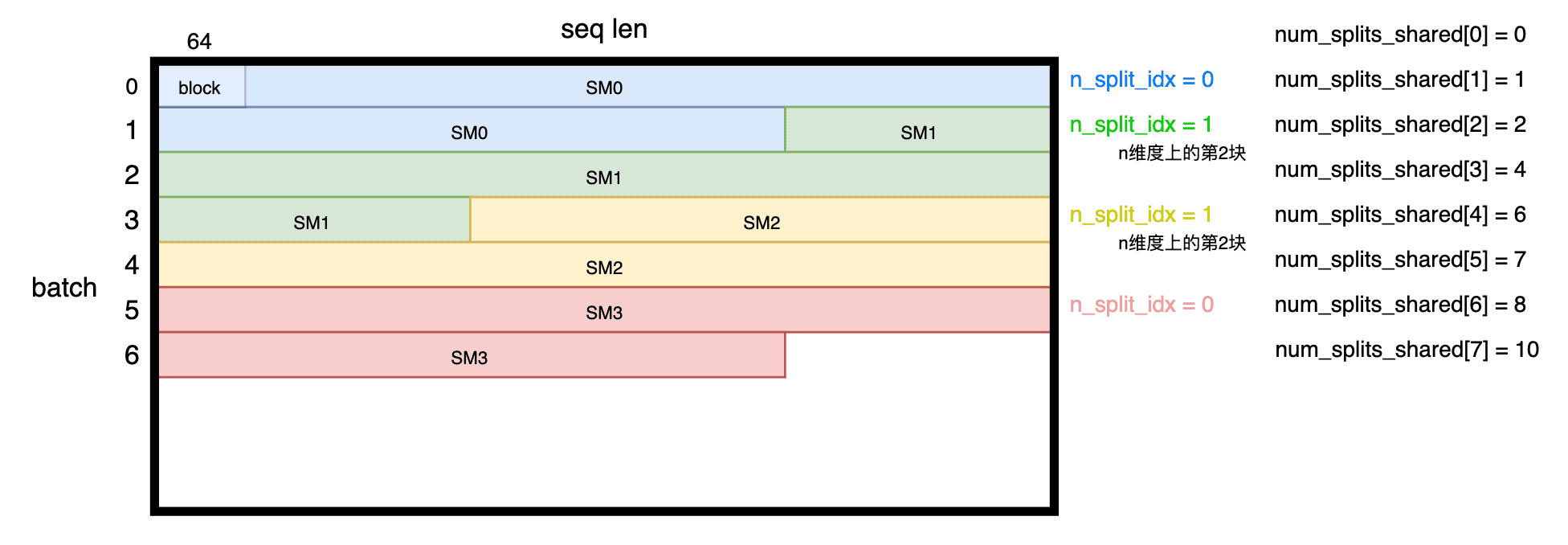
别的都好懂,结合源码理解一下 n_split_idx 的意思:
初始payload = cutlass::ceil_div(total_num_blocks, num_sm_parts) + fixed_overhead_num_blocks;
这是每个 SM 部分 需要处理的任务块数量。向上取整保证任务块均匀分配,fixed_overhead_num_blocks是5,用途是 (待补充) 。
在这里我的计算结果是 ceil(8832 / 78) + 5 = 119
第 0 个sm:
now_inx = 0 --> begin_idx = 0
now_block = 0 --> begin_seqlen = 0 * 64 = 0
n_split_idx = 0
进入while:
- now_blocks = 0, num_blocks = 64 --> now_remain_blocks = 64
- remain_payload = 119 VS now_remain_blocks +
fixed_overhead_num_blocks = 69
- 足够覆盖,还有剩余 50 --> cum_num_splits + 1 (累积拆分数量)
- remain_payload = 50 VS now_remain_blocks + fixed_overhead_num_blocks
= 69
- 不够,now_block = remain_payload - fixed_overhead_num_blocks = 45
- now_n_split_idx++ (这一行需要多拆一次)
第 1 个sm:
now_inx = 1 --> begin_idx = 1
now_block = 45 --> begin_seqlen = 45 * 64 = 2880
n_split_idx = 1(代表这是在处理拆分后的第1部分)
进入while:
- now_blocks = 45, num_blocks = 64 --> now_remain_blocks = 19 (上一次的还有19个block没处理完)
- remain_payload = 119 VS now_remain_blocks +
fixed_overhead_num_blocks = 24
- 足够覆盖,还有剩余 95 --> cum_num_splits + 1 (累积拆分数量)
- remain_payload = 95 VS now_remain_blocks + fixed_overhead_num_blocks
= 69
- 足够覆盖,还有剩余 26 --> cum_num_splits + 1 (累积拆分数量)
- remain_payload = 26 VS now_remain_blocks + fixed_overhead_num_blocks
= 69
- 不够,now_block = remain_payload - fixed_overhead_num_blocks = 21
- now_n_split_idx++ (这一行需要多拆一次)
第 2 个sm:
now_inx = 2 --> begin_idx = 1
now_block = 21 --> begin_seqlen = 21 * 64 = 1344
n_split_idx = 1(代表这是在处理拆分后的第1部分)
……
也就是说,这里分了 78 个sm_parts,在这个例子里,每个sm_parts会处理多行,如果有一行没处理完,就要 n_split_idx + 1。也就是说,对于 SM 来说,n_split_idx 表示的是n维度的第几块的索引。
1.2.2 paged
attention计算 flash_mla_with_kvcache
回到主线,看flash_mla_with_kvcache 函数
1 | flash_mla_with_kvcache( |
| shape(value) | ||
|---|---|---|
q |
[128, 1, 32, 576] | (batch_size, seq_len_q, num_heads_q, head_dim) |
blocked_k |
[8192, 64, 1, 576] | (num_blocks, page_block_size, num_heads_k, head_dim) |
block_table |
[128, 64] | (batch_size, max_num_blocks_per_seq), torch.int32 |
cache_seqlens |
[128] | (batch_size), torch.int32 |
dv |
512 | Head_dim of v |
tile_scheduler_metadata |
[78, 8] | (num_sm_parts, TileSchedulerMetaDataSize), torch.int32 |
num_splits |
[129] | (batch_size + 1), torch.int32 |
要注意,这里的 q 已经吸收了kv的变换矩阵,所以后面可以直接对合并的 kvcache 计算
在 flash_api.cpp 里,mha_fwd_kvcache_mla ->
run_mha_fwd_splitkv_mla ->
run_flash_splitkv_fwd_mla 函数 lunch 了两个 kernel:
- flash_fwd_splitkv_mla_kernel
- flash_fwd_splitkv_mla_combine_kernel
这两个 kernel 是同一个 stream,是顺序执行的一个关系。
1 | template<typename Kernel_traits, typename SharedStorage> |
逐句解析一下:
- 通过计算
num_m_block计算在 M 维度上所需要的块数, 计算是在M方向切分 block,在 seq len 方向进行 n_block 的loop。其中,blockM=64,blockN=64。
num_m_block = cute::ceil_div(params.seqlen_q, Kernel_traits::kBlockM);
在我的例子中,h_q(即 params.seqlen_q) = 32,不够 blockM, 所以计算出来的 num_m_block = 1.
flash_fwd_splitkv_mla_kernel这个内核函数会根据 Kernel_traits 和 Is_causal 的值进行特化。smem_size: 计算共享内存的大小,
SharedStorage是一个用于存储共享数据的结构体,大小通过sizeof获取。然后通过 调用cudaFuncSetAttribute函数为内核设置最大动态共享内存的大小。
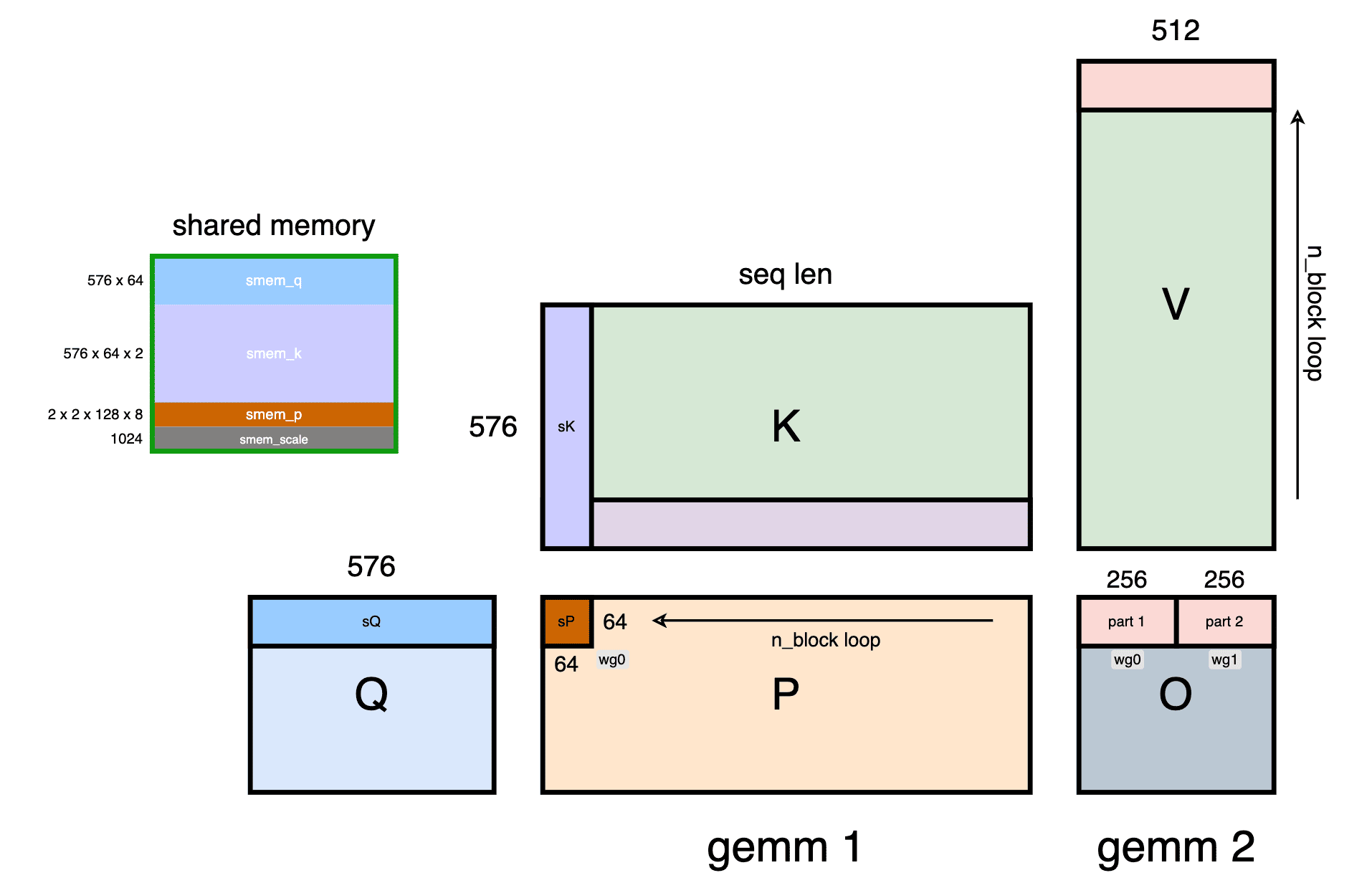
这里值得仔细算一下:smem_size = 230400 (224KB)
union{
struct{
- smem_q: 73728
- 存放输入Q
- 576 * 64 * 2B / 1024 = 72 KB
- smem_k: 73728 * 2 = 147456 (Double buffer)
- 存放输入K(包含部分V)
- 64 * 576 * 2B * 2 / 1024 = 144KB
- smem_p: 8192
- 用于存放 gemm 1 的结果,用于 `wg 0` 和 `wg 1` 之间的数据中转
- 2 x 2 x 128 x 8 x 2B / 1024 = 8KB
- smem_scale: 1024
}
struct{
- smem_max: 1024
- smem_sum: 1024
- smem_o : 131072
}
}| Data Center GPU | NVIDIA V100 | NVIDIA A100 | NVIDIA H100 |
|---|---|---|---|
| GPU architecture | NVIDIA Volta | NVIDIA Ampere | NVIDIA Hopper |
| Compute capability | 7.0 | 8.0 | 9.0 |
| Shared memory size / SM | Configurable up to 96 KB | Configurable up to 164 KB | Configurable up to 228 KB |
smem_size 是 224KB,而 Hopper 架构的 Shared memory size 是228KB, 这么看的话,确实只有 Hopper 架构的卡能完美跑这个算法了。
- kernel<<<...>>>: 启动 CUDA 核函数
kernel,设置其 grid size 和 block size。
- dim3(num_m_block, params.h, params.num_sm_parts) 是执行的 grid 大小
- dim3(1, num_heads = 1, 78)
- Kernel_traits::kNThreads 是每个线程块中的线程数量
- 256
- smem_size 是共享内存大小
- 230400
- stream 是 CUDA 流
- 因为 params.num_sm_parts 是 78,所以在
MLA_NUM_SPLITS_SWITCH中会将kMaxSplits设置为 96。
1 | MLA_NUM_SPLITS_SWITCH(params.num_sm_parts, kMaxSplits, [&] { |
启动 CUDA 核函数 combine_kernel,
- combine_kernel<<<grid_combine, 128, 0, stream>>>
- grid_combine: 是一个一维的 dim3 类型,表示合并内核的网格大小。
- 只给出一个数字时,CUDA 会默认将它映射到 x 维度,并将 y 和 z 维度设置为 1
- dim3(batch_size * num_heads * seqlen_q = 128 * 1 * 32 = 4096, 1, 1)
- 这个 combine_kernel 没有分配额外的动态共享内存
接下来看这两个kernel。
1.2.2.1 flash_fwd_splitkv_mla_kernel
- dim3(num_m_block, params.h, params.num_sm_parts)
- dim3(1, num_heads = 1, 78)
1 |
|
我们聚焦在 SM1 上,对应的 begin_idx = 1, end_idx = 3, 于是会进行3次循环:
| batch_id | n_split_idx | seqlen_k | n_block_min | n_block_max | NoSplit |
|---|---|---|---|---|---|
| 1 | 1 | 4096 | 45 | 64 | 0 |
| 2 | 0 | 4096 | 0 | 64 | 1 |
| 3 | 0 | 4096 | 0 | 21 | 0 |
进一步看 compute_attn_1rowblock_splitkv_mla 函数:
首先是一些参数:
- kBlockM = 64
- kBlockN = 64
- kHeadDim = 576
- kHeadDimV = 512
- kNThreads = 256
- kNThreadsS = 128
1 | /// Returns a warp-uniform value indicating the canonical warp group index of the calling threads. |
使用 cutlass::canonical_warp_group_idx();
函数对每个thread block 的 256 thread 进行了分组,分成了2个warp
group。也就是 0-127 thread是 wg0, 128-255
thread是wg1.
接下来的代码逻辑,画图反而表达得比较清楚一些:
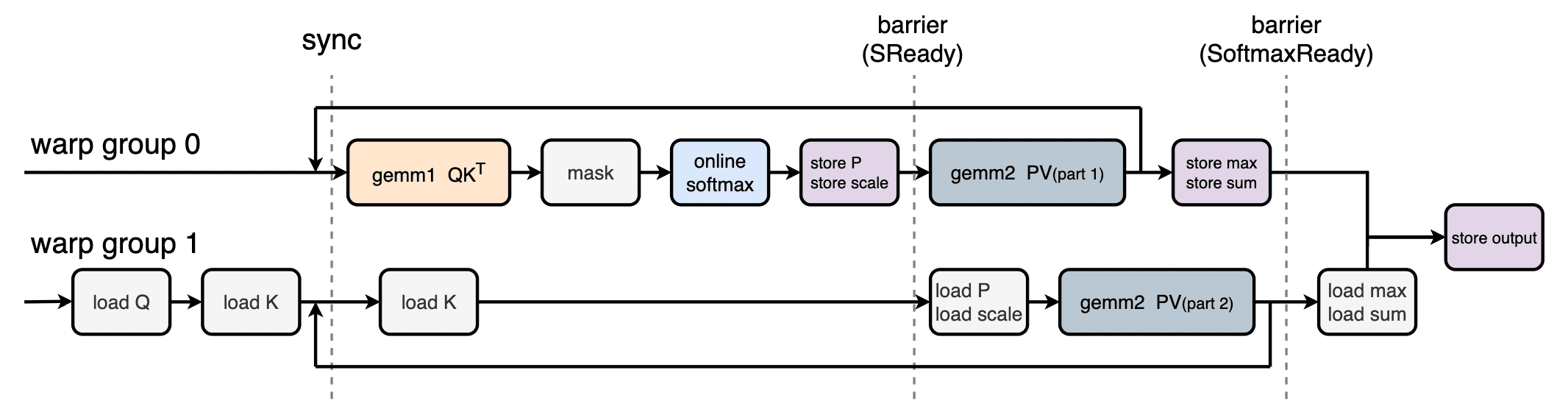
warp group 0:
1 | typename Kernel_traits::TiledMma tiled_mma; |
为线程分配矩阵片段,以便进行矩阵乘法(MMA)操作
1 | if (n_block % 2 == 1) { |
这里是 Double buffer 逻辑,如果 n_block 是奇数的话,要加上 sK_offset / 8 的偏移。
- 为什么是 sK_offset / 8 呢?我理解的是单个wgmma为64x64x16,这里的 8 是 64 * 2 / 16。
1 | for (int masking_step = n_masking_steps; n_block >= n_block_min; --masking_step, --n_block) { |
for循环是沿着 n_block 做了一个遍历
每一次循环分别做了 gemm1 的计算,mask操作,online softmax 以及存储计算结果的操作。
tiled_mma shape是64,64,576,单个wgmma为 64x64x16,k方向循环迭代。
tiled_mma_o shape是64,512,64, 在 N 的方向切成2个mma,单个wgmma为64x256x16,warp group 0计算其中的一部分,
warp group 1:
wg1 负责加载 Q K P,做 tiled_mma_o 的第二部分计算。
有意思的是,wgmma最大支持N=256,刚好是headdimV的一半,因此两个warp group刚好完成一整个gemm 2的计算。LingYe
加载这个动作用 block_table 进行索引,通过 n_block 的奇偶性切换 KV 的 buffer。
在 n_block loop 结束完成后,通过 SoftmaxReady 做了一个 sum/max 的同步,让两个warp group都取得相同的数据,最后一起做stroe output。
MLA kernel 之后还有combine kernel,去 reduce num_sm_parts partial result 得到完整结果。
1.2.3 flash_fwd_splitkv_mla_combine_kernel
- dim3(batch_size * num_heads * seqlen_q = 128 * 1 * 32 = 4096, 1, 1)
这个 kernel 处理基于 splitkv 的计算,执行加法操作、softmax 求和以及其他张量操作。
1 | const int split_offset = __ldg(params.num_splits_ptr + batch_idx); |
通过从 params.num_splits_ptr 中读取当前批次的 split 数量,并检查 actual_num_splits 是否大于 kMaxSplits。 如果 actual_num_splits == 1,则提前返回,不做计算。
这要又一次结合这张图来看了
- batch_idx = 0 --> actual_num_splits = 1 --> return
- batch_idx = 1 --> actual_num_splits = 2 --> ...
- batch_idx = 2 --> actual_num_splits = 1 --> return
- batch_idx = 3 --> actual_num_splits = 3 --> ...
这一块代码进行了 LSE 的计算:计算最大值, 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28int warp_idx = cutlass::canonical_warp_idx_sync(); // 32个线程一个warp
if (warp_idx == 0) { // 只有 0-31 线程
constexpr int kNLsePerThread = cute::ceil_div(kMaxSplits, 32);
float local_lse[kNLsePerThread];
for (int i = 0; i < kNLsePerThread; ++i) {
const int split = i * 32 + tidx;
local_lse[i] = split < actual_num_splits ? gLSEaccum(split) : -INFINITY;
}
float max_lse = -INFINITY;
for (int i = 0; i < kNLsePerThread; ++i) max_lse = max(max_lse, local_lse[i]);
for (int offset = 16; offset >= 1; offset /= 2) max_lse = max(max_lse, __shfl_xor_sync(uint32_t(-1), max_lse, offset));
max_lse = max_lse == -INFINITY ? 0.0f : max_lse; // In case all local LSEs are -inf
float sum_lse = 0;
for (int i = 0; i < kNLsePerThread; ++i) sum_lse = sum_lse + expf(local_lse[i] - max_lse);
for (int offset = 16; offset >= 1; offset /= 2) sum_lse = sum_lse + __shfl_xor_sync(uint32_t(-1), sum_lse, offset);
float global_lse = (sum_lse == 0.f || sum_lse != sum_lse) ? INFINITY : logf(sum_lse) + max_lse;
if (tidx == 0) gLSE(0) = global_lse;
for (int i = 0; i < kNLsePerThread; ++i) { //存储每个split的lse缩放系数到共享内存中
const int split = i * 32 + tidx;
if (split < actual_num_splits) sLseScale[split] = expf(local_lse[i] - global_lse);
}
}
__syncthreads();
对每个split进行加权求和,结果在 tOrO 张量中
1 | for (int split = 0; split < actual_num_splits; ++split) { |
最终对结果做一下类型转换和存储到 global memory 中。
这个 kernel 主要就是在每个线程块内计算和合并多个 split 的结果,使用 softmax 的 LSE 计算和缩放系数进行加权求和。
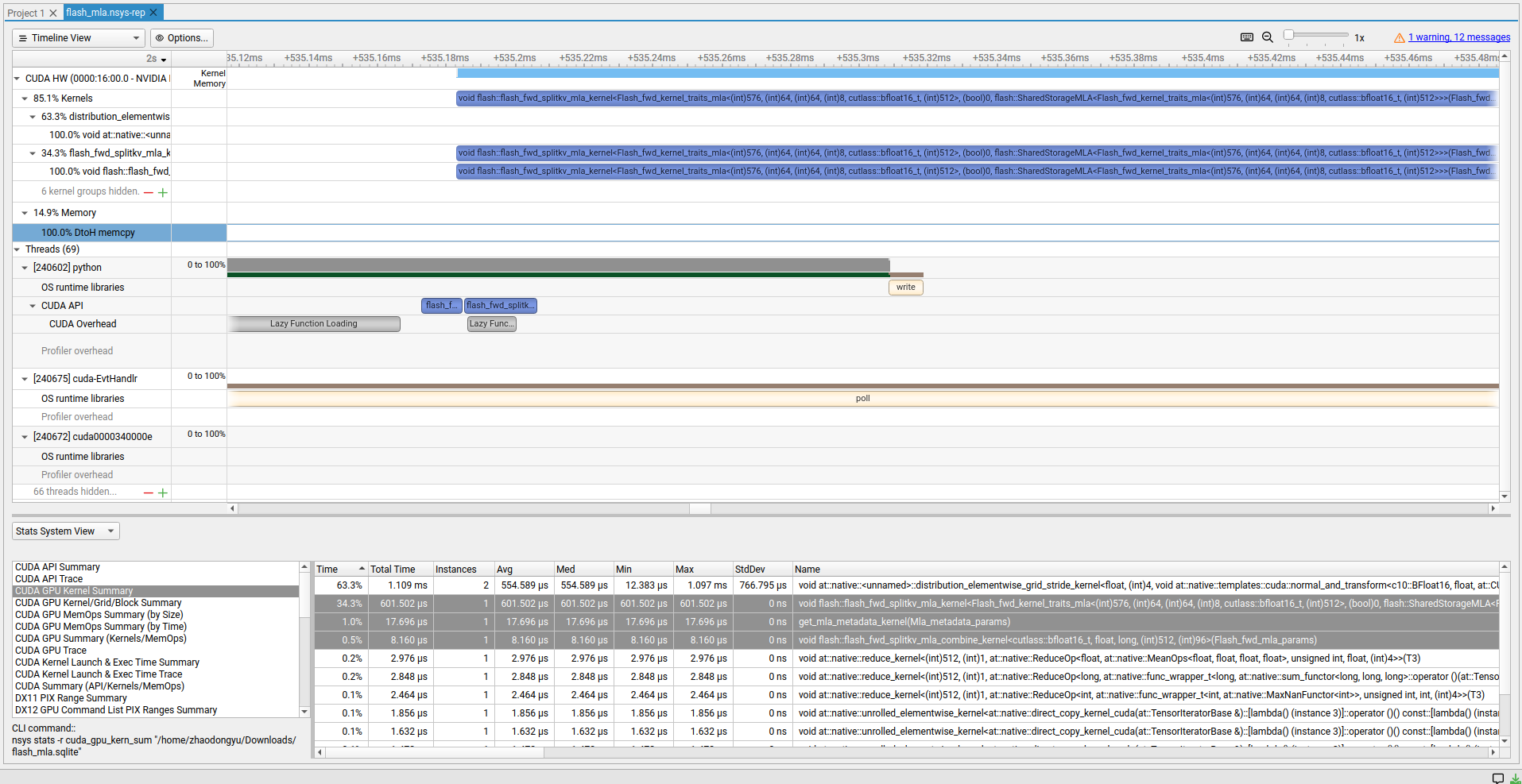
2.性能查看
使用 nsight system 简单看一下 kernel 的耗时:
nsys profile --trace=cuda,osrt -o flash_mla --force-overwrite true python tests/test_flash_mla.py
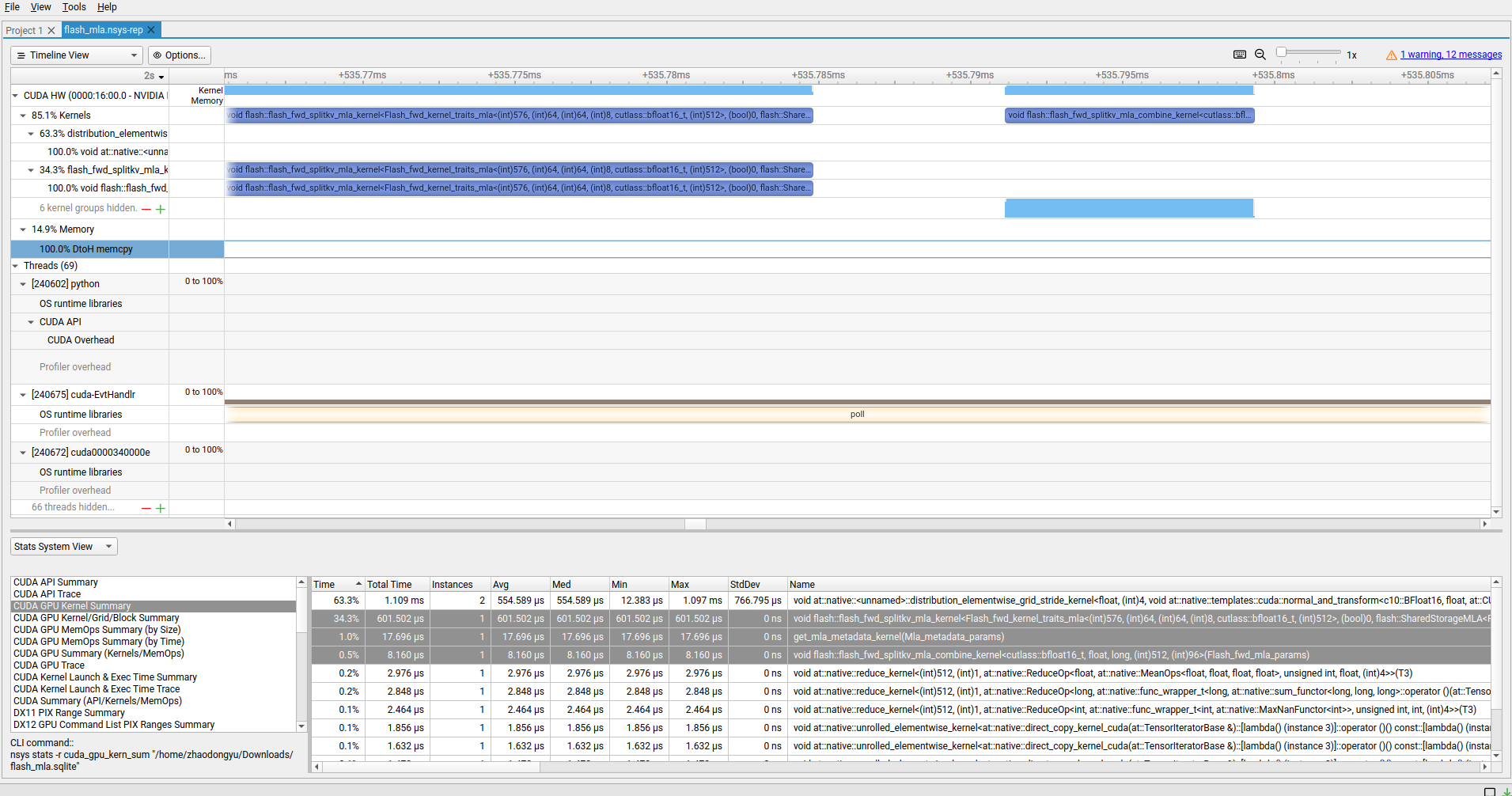
和MLA有什么关系?
之前看了一些关于讲解 MLA 的文章,如 苏剑林 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA 和 ZHANG Mingxing DeepSeek-V2 高性能推理 (1):通过矩阵吸收十倍提速 MLA 算子
看算子的时候就一直在好奇,这不就是在算 attention 吗?W^UQ W^UK 这些投影矩阵完全没出现啊,那这和 MLA 有什么关系呢?
后来才知道,这些已经被矩阵吸收到 Q 矩阵了,这个 FlashMLA 就是在做针对 MLA 维度的高效推理。
总结
MLA本质上是一个KV部分共享的,升维的MQA。维度从一般的128升维到576/512,KV共享前512长度,另有64长度是K独有的。 flashMLA只能在hopper架构上运行,几乎无法移植到其他平台。(除非有大于228KB的share memory,有N大于256的wgmma) flashMLA利用了online softmax算法、paged attn的分块和split-kv优化,叠加自己的计算mapping和两个warp group相配合的流水线,达到了很高的性能。LingYe
在 ZHANG
Mingxing 的 git 里还有关于 move_elision
的优化,效果显著,但是我看 FlashMLA
没有用到,不知道用上的话会有什么影响。
认真读完代码之后学习到很多 Cuda 算子设计的巧妙之处,受益良多,接下来开始尝试将 FlashMLA 用起来,以及学习 Deepseek 开源的其他工程。
小白一枚,理解浅显,有问题的部分还希望大佬们指正~


