扎实基础,系统学习。
how-to-learn-deep-learning-framework
how-to-optim-algorithm-in-cuda
接下来要花时间学习这个 [gpu-mode/lectures][https://github.com/gpu-mode/lectures]
Deepseek
技术报告 - Multi-head Latent Attention (MLA) for efficient inference
[Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.](https://arxiv.org/abs/2405.04434)DeepSeekMoE for cost-effective training
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
MOE
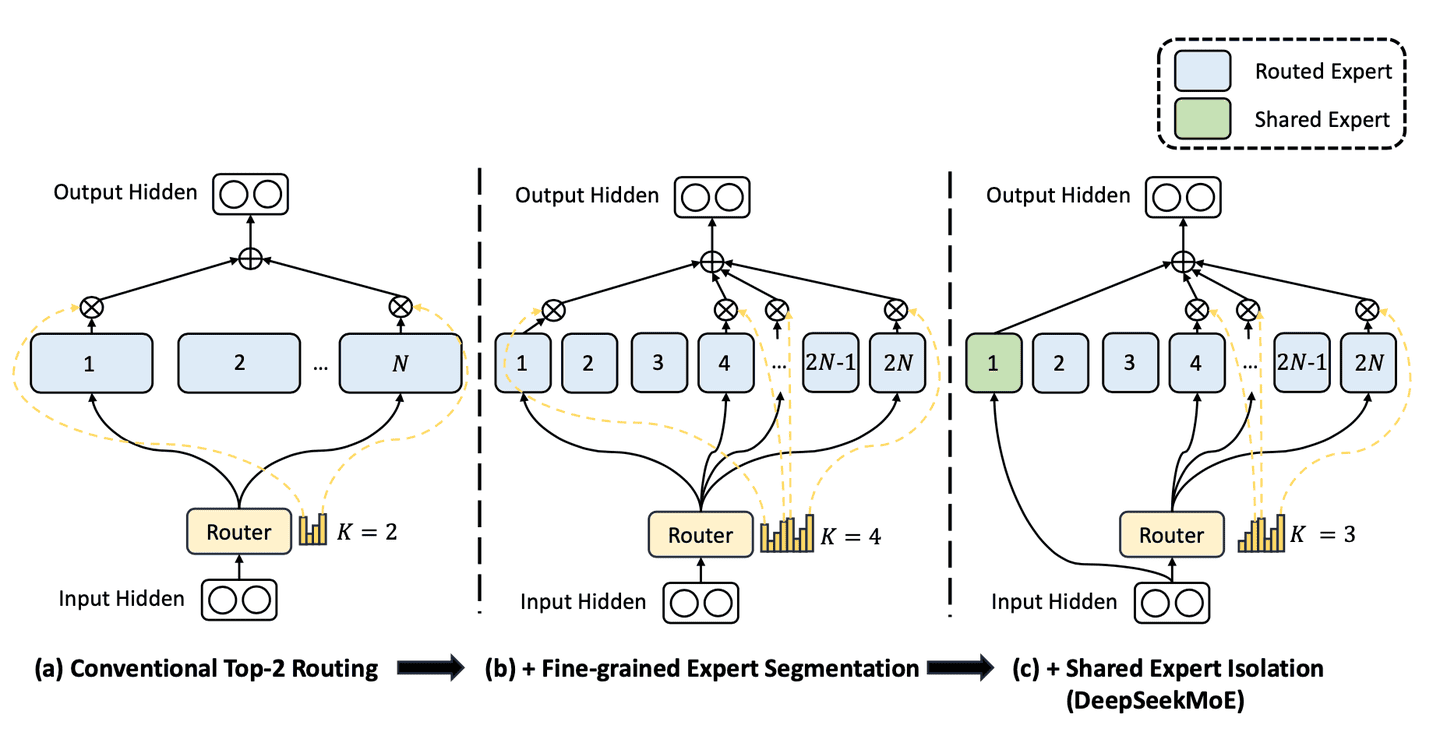
从 GShard 到 DeepSeek-V3,我们不难发现负载均衡已经成为 MoE 模型能否取得成功的关键因素之一。 - GShard 提出了 top-2 gating 和容量限制的雏形; - Switch 用 top-1 gating 证明了简单路由也能支撑大规模; - GLaM 强调能效;DeepSpeed-MoE 则兼顾了训练和推理; - ST-MoE 用 z-loss 解决稳定性; - Mixtral 强调路由的时间局部性; - OpenMoE 暴露了末端 token 掉队等问题; - JetMoE 尝试 dropless; - DeepSeekMoE 做了细粒度拆分和共享专家; - 最后,DeepSeek-V3 又带来了更“轻量级”的偏置调节策略。
主要启示:负载均衡永远在动态平衡——过度干预会损害模型本身的学习目标,完全无视则会出现专家闲置或拥堵。往后我们大概率会看到更多 HPC 技巧与更灵活的 gating 机制,以及更多针对推理部署的优化。
从这里跳到小宇宙听了三小时的 DeepSeek论文的逐句讲解 - 接近3个小时的高密度输出,非常能杀脑细胞,但杀完之后分泌出来的内啡肽,也含量爆炸。


