学习研究文生视频
Effective scaling strategy 将计算资源需求减少最多5倍,同时实现预期的模型性能。
13 billion parameters 130亿参数 pre-training it on internet-scale images and videos. 在互联网规模的图像和视频上进行了预训练。
在视频生成的四个关键方面表现出色: - 视觉质量 visual quality - 运动动态 motion dynamics - 视频与文本对齐 video-text alignment - 语义场景切换 semantic scene cut
第3部分介绍了我们的数据预处理技术,包括数据过滤和重新标注模型。 第4部分详细介绍了鸿源视频所有组件的架构,以及我们的训练和推理策略。 第5部分讨论了加速模型训练和推理的方法,从而支持130亿参数的大型模型开发。 第6部分评估了我们的文本到视频基础模型的性能,并将其与开源和闭源的顶尖视频生成模型进行比较。
image-video joint training strategy 图像-视频联合训练策略
对于形状为 (T + 1) × 3 × H × W 的视频,我们的3D VAE将其压缩为形状为 (T/ct + 1) × C × (H/cs) × (W/cs) 的潜在特征。
This compression significantly reduces the number of tokens for the subsequent diffusion transformer model, allowing us to train videos at the original resolution and frame rate.
中文: 这种压缩显著减少了后续扩散Transformer模型的Token数量,使我们能够在原始分辨率和帧率下训练视频。
在单个GPU上编码和解码高分辨率长视频可能会导致内存不足(OOM)错误。为了解决这个问题,我们使用了时空切片策略spatial-temporal tiling strategy,将输入视频在空间和时间维度上分割为重叠的切片。 每个切片分别进行编码/解码,然后将输出拼接在一起。对于重叠区域,我们使用线性组合 linear combination 进行融合。 这种切片策略使我们能够在单个GPU上编码/解码任意分辨率和时长的视频。
推理过程中直接使用切片策略可能会由于训练和推理的不一致性而导致明显的伪影。 为了解决这个问题,我们引入了一个额外的微调阶段,在训练过程中随机启用或禁用切片策略。
对于文本分支,我们首先使用先进的大语言模型(LLM)将文本编码为捕捉细粒度语义信息的嵌入序列。 同时,我们使用CLIP模型提取包含全局信息的池化文本表示。这种表示随后在维度上进行扩展,并在输入模型前添加到时间步 timestep embedding 嵌入中。 CLIP model: 一种预训练模型,可生成文本和图像的嵌入表示。
为了有效整合文本和视觉信息,我们采用了与[47]中视频生成类似的“双流到单流Dual-stream to Single-stream”混合模型设计策略。 在双流阶段,视频和文本Token通过多个Transformer块独立处理,使每种模态能够学习各自适当的调节机制,而不受干扰。 在单流阶段,我们将视频和文本Token拼接后输入后续Transformer块,以实现有效的多模态信息融合。 这种设计捕捉了视觉和语义信息之间的复杂交互,提升了整体模型性能。
在其生成模型中使用了基于扩散的骨干网络,建立在扩散概率模型的最新进展之上。 骨干网络在潜在空间中运行,处理由3DVAE编码器提取的Token序列。 核心网络结构采用基于Transformer的U-Net设计,集成了时空注意力层和前馈模块。
对于文本分支,我们采用了一种双层方法,将大规模预训练语言模型(LLM)与CLIP模型结合起来。 第一层使用LLM提取细粒度的文本特征,捕捉详细的语义信息。 接下来是CLIP模型,将嵌入池化为一个全局文本表示,用于总结输入文本的整体语境。 两种模型的组合嵌入随后作为输入,传递给视频生成骨干网络。 通过整合两层特征,文本编码器有效平衡了细粒度细节和全局语境,实现了精确的文本与视频对齐。
dist.init_process_group("nccl")
初始化分布式训练过程,设置进程间的通信方式,特别是使用 NCCL(NVIDIA Collective Communications Library)作为通信后端。
是 PyTorch 分布式训练中的一个重要步骤,用于初始化分布式环境,使得多个进程可以通过通信框架互相协调工作。
NCCL 是一个高效的分布式通信库,特别优化了在 NVIDIA GPU
上进行数据传输和集合操作(如
all-reduce,all-gather)的性能。它能够利用 GPU
内部的高速互联(如
NVLink、PCIe)进行通信,提供低延迟、高带宽的数据交换。
工作原理 -
多机训练:如果有多个机器,每个机器上可能有多个
GPU,这时 init_process_group("nccl")
会通过网络将各机器上的进程连接起来。 -
单机多卡训练:如果只在一台机器上使用多个
GPU,这个初始化过程会使得不同 GPU 之间可以高效地共享数据。 -
通信模式:在 NCCL 后端的帮助下,PyTorch 可以进行高效的
all-reduce(将多个 GPU
上的梯度合并),broadcast(将一个 GPU 的数据广播到其他
GPU)等操作。
ring_degree ulysses_degree https://github.com/xdit-project/xDiT/tree/main
𝒑: Number of pixels;
𝒉𝒔: Model hidden size;
𝑳: Number of model layers;
𝑷: Total model parameters;
𝑵: Number of parallel devices;
𝑴: Number of patch splits;
𝑸𝑶: Query and Output parameter count;
𝑲𝑽: KV Activation parameter count;
𝑨 = 𝑸 = 𝑶 = 𝑲 = 𝑽: Equal parameters for Attention, Query, Output, Key,
and Value;
| attn-KV | communication cost | param memory | activations memory | extra buff memory | |
|---|---|---|---|---|---|
| Tensor Parallel | fresh | \(4O(p \times hs)L\) | \(\frac{1}{N}P\) | \(\frac{2}{N}A = \frac{1}{N}QO\) | \(\frac{2}{N}A = \frac{1}{N}KV\) |
| DistriFusion* | stale | \(2O(p \times hs)L\) | \(P\) | \(\frac{2}{N}A = \frac{1}{N}QO\) | \(2AL = (KV)L\) |
| Ring Sequence Parallel* | fresh | \(2O(p \times hs)L\) | \(P\) | \(\frac{2}{N}A = \frac{1}{N}QO\) | \(\frac{2}{N}A = \frac{1}{N}KV\) |
| Ulysses Sequence Parallel | fresh | \(\frac{4}{N}O(p \times hs)L\) | \(P\) | \(\frac{2}{N}A = \frac{1}{N}QO\) | \(\frac{2}{N}A = \frac{1}{N}KV\) |
| PipeFusion* | stale- | \(2O(p \times hs)\) | \(\frac{1}{N}P\) | \(\frac{2}{M}A = \frac{1}{M}QO\) | \(\frac{2L}{N}A = \frac{1}{N}(KV)L\) |
看 communication cost 的话, Ulysses Sequence Parallel 更小一些,
Ring Sequence Parallel 和 Ulysses Sequence Parallel 是分布式计算中用于并行化序列模型(如 Transformer)的两种策略。它们的主要区别在于如何分割和处理数据流,以及它们在模型中的实现方式。
| 特性 | Ring Sequence Parallel | Ulysses Sequence Parallel |
|---|---|---|
| 数据分割方式 | 小块,按时间步或序列依赖分割 | 较大块,按长序列分割 |
| 设备间依赖性 | 强依赖,顺序传递 | 较弱依赖,尽量独立处理 |
| 通信模式 | 环形通信,设备间按序依赖 | 较少通信,设备间松耦合 |
| 适用任务 | 时间步序列任务(RNN-like) | 长序列模型(Transformer-like) |
| 计算效率 | 较低,因需等待前一设备完成 | 较高,因设备独立并行工作 |
| 实现复杂度 | 较低,容易实现 | 较高,需复杂的分割与同步策略 |
选择的考量 - 如果模型需要严格的时间步依赖(如 RNN)且通信开销可以接受,Ring Sequence Parallel 是一个适合的选择。 - 如果模型是基于长序列(如 GPT 或 BERT 的长文档处理),并且需要最大化并行效率,Ulysses Sequence Parallel 更为理想。
args = Namespace(model='HYVideo-T/2-cfgdistill', latent_channels=16, precision='bf16', rope_theta=256, vae='884-16c-hy', vae_precision='fp16', vae_tiling=True, text_encoder='llm', text_encoder_precision='fp16', text_states_dim=4096, text_len=256, tokenizer='llm', prompt_template='dit-llm-encode', prompt_template_video='dit-llm-encode-video', hidden_state_skip_layer=2, apply_final_norm=False, text_encoder_2='clipL', text_encoder_precision_2='fp16', text_states_dim_2=768, tokenizer_2='clipL', text_len_2=77, denoise_type='flow', flow_shift=7.0, flow_reverse=True, flow_solver='euler', use_linear_quadratic_schedule=False, linear_schedule_end=25, model_base='ckpts', dit_weight='ckpts/hunyuan-video-t2v-720p/transformers/mp_rank_00_model_states_fp8.pt', model_resolution='540p', load_key='module', use_cpu_offload=True, batch_size=1, infer_steps=50, disable_autocast=False, save_path='./results', save_path_suffix='', name_suffix='', num_videos=1, video_size=[960, 544], video_length=129, prompt='A cat walks on the grass, realistic style.', seed_type='auto', seed=42, neg_prompt=None, cfg_scale=1.0, embedded_cfg_scale=6.0, use_fp8=True, reproduce=False, ulysses_degree=1, ring_degree=1)
VAE学习 https://www.gwylab.com/note-vae.html
llava-llama-3-8b-v1_1-hf is a LLaVA model fine-tuned from meta-llama/Meta-Llama-3-8B-Instruct and CLIP-ViT-Large-patch14-336 with ShareGPT4V-PT and InternVL-SFT by XTuner.
是的,llava-llama-3-8b-v1_1-hf 是一个典型的 MLLM(多模态大语言模型)的实例。
为什么是 MLLM?
这个模型的架构和功能体现了多模态大语言模型的特点: 1. 多模态能力: • 它结合了文本(LLaMA 模型)和视觉信息(CLIP 模型),能够处理图像和文本两种模态的数据。 • 通过 CLIP 的视觉编码器(CLIP-ViT-Large-patch14-336)来提取图像特征,文本部分由 Meta-Llama-3-8B-Instruct 处理。 2. 大语言模型(LLM)能力: • 使用 Meta 的 Llama 3 模型,这是一种强大的文本生成和理解语言模型,经过指令微调(Instruct Tuning),适合对话和任务式问答。 3. 多模态数据的联合微调: • 使用数据集 ShareGPT4V-PT 和 InternVL-SFT,对多模态输入(图像+文本)进行强化训练。 • ShareGPT4V-PT:包含 ChatGPT 和 GPT-4 Vision 提供的多模态对话数据。 • InternVL-SFT:一种视觉-语言领域的任务微调数据集。 4. 模型设计: • 结合 LLaVA(Large Language and Vision Assistant) 框架,用于多模态问答(Multimodal Q&A),可以同时处理图像和文本输入,生成多模态输出。
LLaVA 是 MLLM 的典型实现
LLaVA(Large Language and Vision Assistant) 系列模型本身就是多模态大语言模型(MLLM)的重要代表之一,结合了强大的视觉编码器(如 CLIP)和语言模型(如 LLaMA)的能力,能够在以下多模态任务中表现优异: • 图文问答(Visual Question Answering, VQA): • 输入图片和问题,回答与图片相关的问题。 • 图像描述生成(Image Captioning): • 输入图片,生成详细的文字描述。 • 图文对话(Multimodal Dialogue): • 在对话中理解并回应图像内容与文本问题的混合输入。
llava-llama-3-8b-v1_1-hf 就是这个方向的具体实现之一。
总结
llava-llama-3-8b-v1_1-hf 是一个典型的多模态大语言模型(MLLM),它结合了强大的文本生成能力和视觉理解能力,是 LLaVA 框架的一个应用实例。
如果你正在探索 MLLM 或者具体想知道它的实现原理、训练过程或应用场景,可以进一步探讨!
Teacache Caching:提速200%,质量无损秘诀! | Speed Boost 200%, No Quality Loss Secrets!
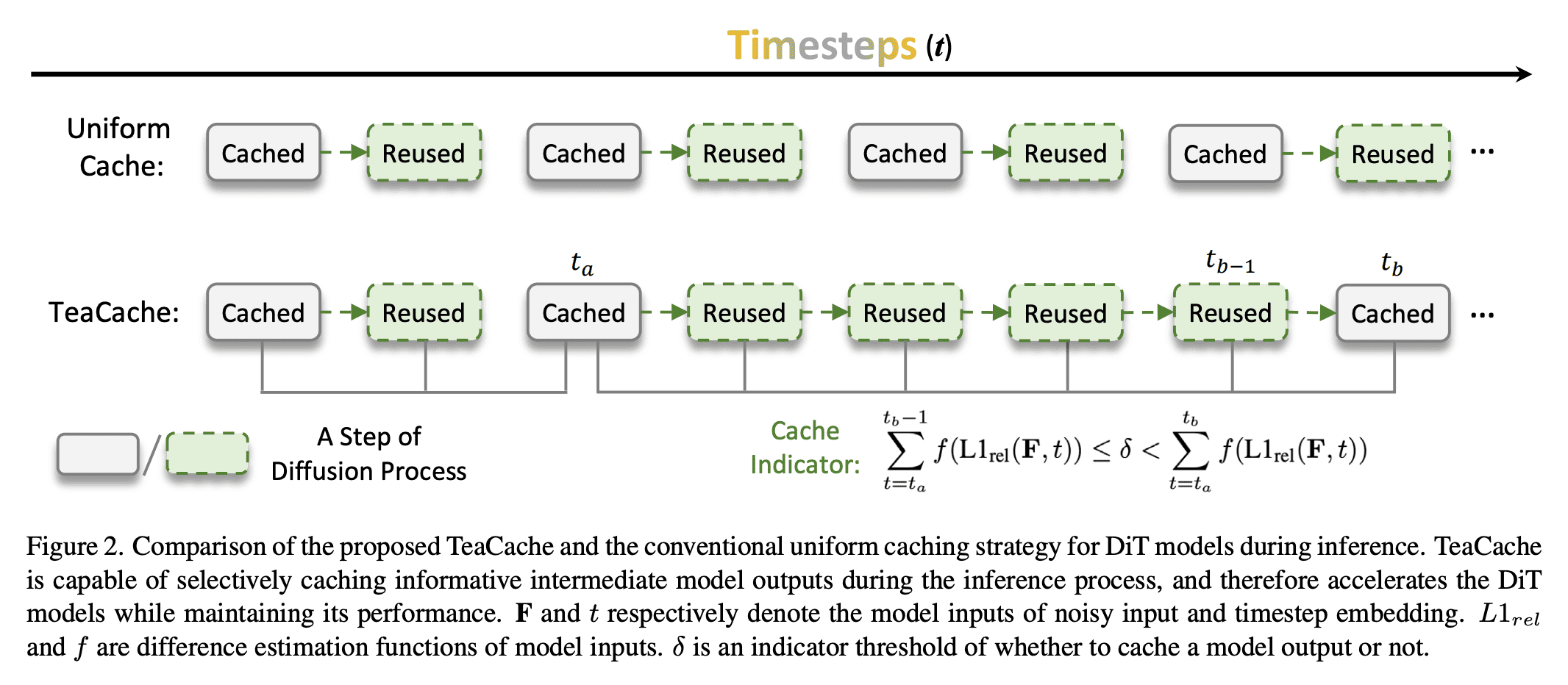
Uniform Cache: 均匀的缓存技术 - 毫无重点 - 没有优化的技术
TeaCache: 非均匀 多次重用 输出取决于输入,输入变化很小 -> 输出变化可以接受,重用缓存,提高缓存效率


