Deploy LLMs for infinite-length inputs without sacrificing efficiency and performance.
背景
两大挑战
在长时间交互的流式应用中,如多轮对话这样的连续聊天,会有两大挑战:
- 在解码阶段,缓存先前标记的键和值状态 (KV) 会消耗大量内存。容易OOM(out of memory)。
- popular LLM 无法推广到比训练序列长度更长的文本。模型性能中断。
内存占用与困惑度
在attention_sinks中指出了这种现象:
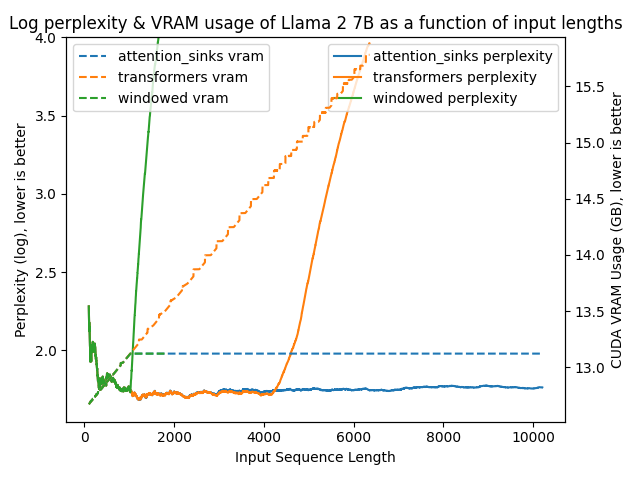
- 简单的 transformer (橙色)
- 内存占用随着输入长度线性增长,容易 OOM。
- 输入长度如果超过训练时的上下文长度,困惑度就会增加。图中在4k长度以后,模型回答质量会很差。(其中这里的4k长度是训练窗口)
- 使用 window attention (绿色)
- 使用有限的、恒定的内存
- 当句子长度超过窗口长度时,困惑度爆炸。因为这时候句子前面的token的 KV cache 会被驱逐。而最前面的几个token非常重要,称之为 attention sink,也就是本文的重点。
- StreamingLLM (蓝色)
- 使用有限的、恒定的内存
- 困惑度一直很低,一直到10k长度(实测到 4M 也ok)
KV Cache
在decoding阶段,要想进行attention计算,需要之前token的 Keys 和 Values。以及需要当前的 Query token。
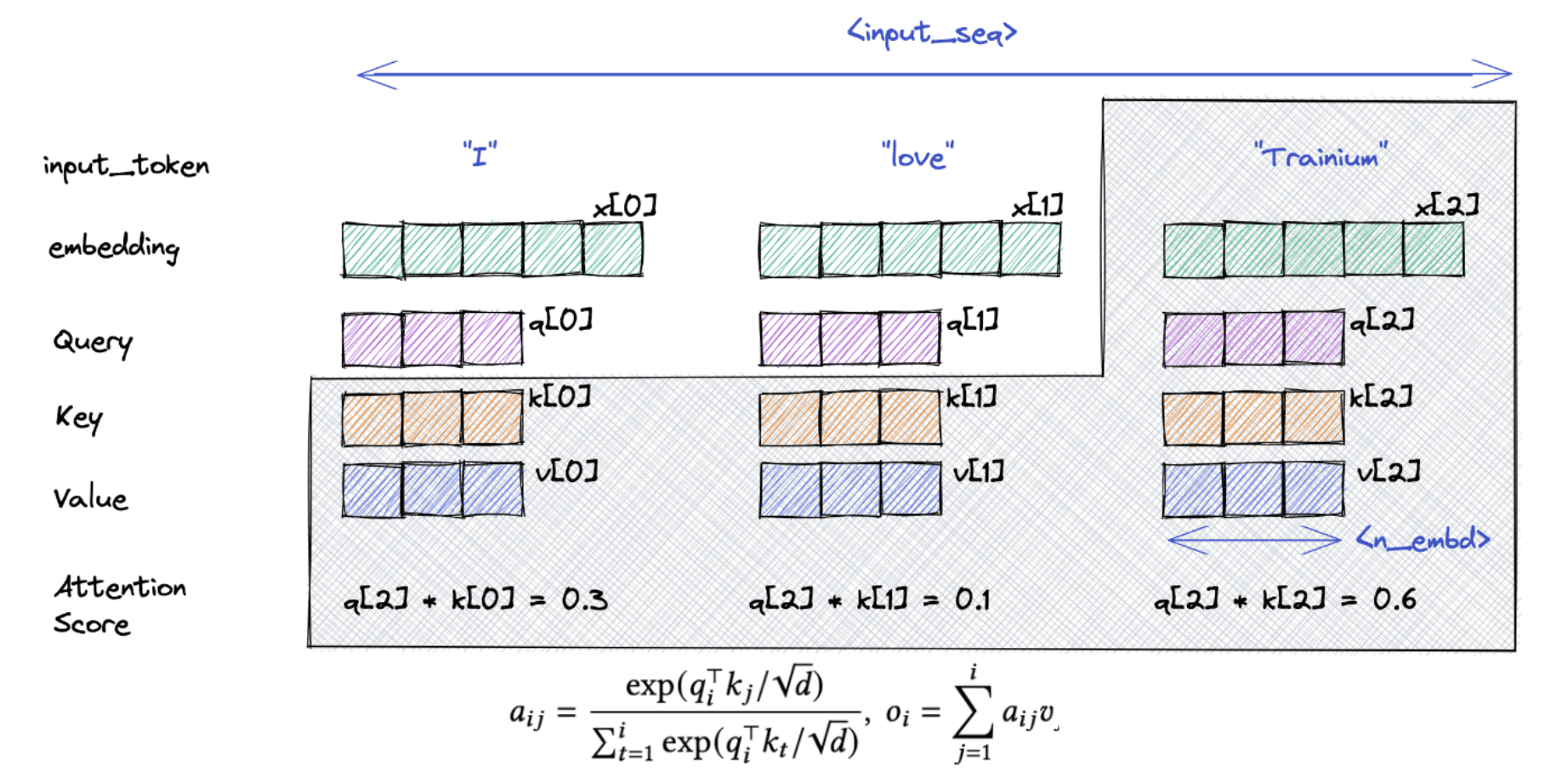
不必在每个 token 生成步骤中重新计算所有先前 token 的 Key 和 Value 向量,而是可以只对当前 token 执行增量计算,并重新使用 KV 缓存中先前计算的 Key/Value 向量。当前 token 的 Key/Value 向量也会附加到 KV 缓存中,以供下一个 token 生成步骤使用。
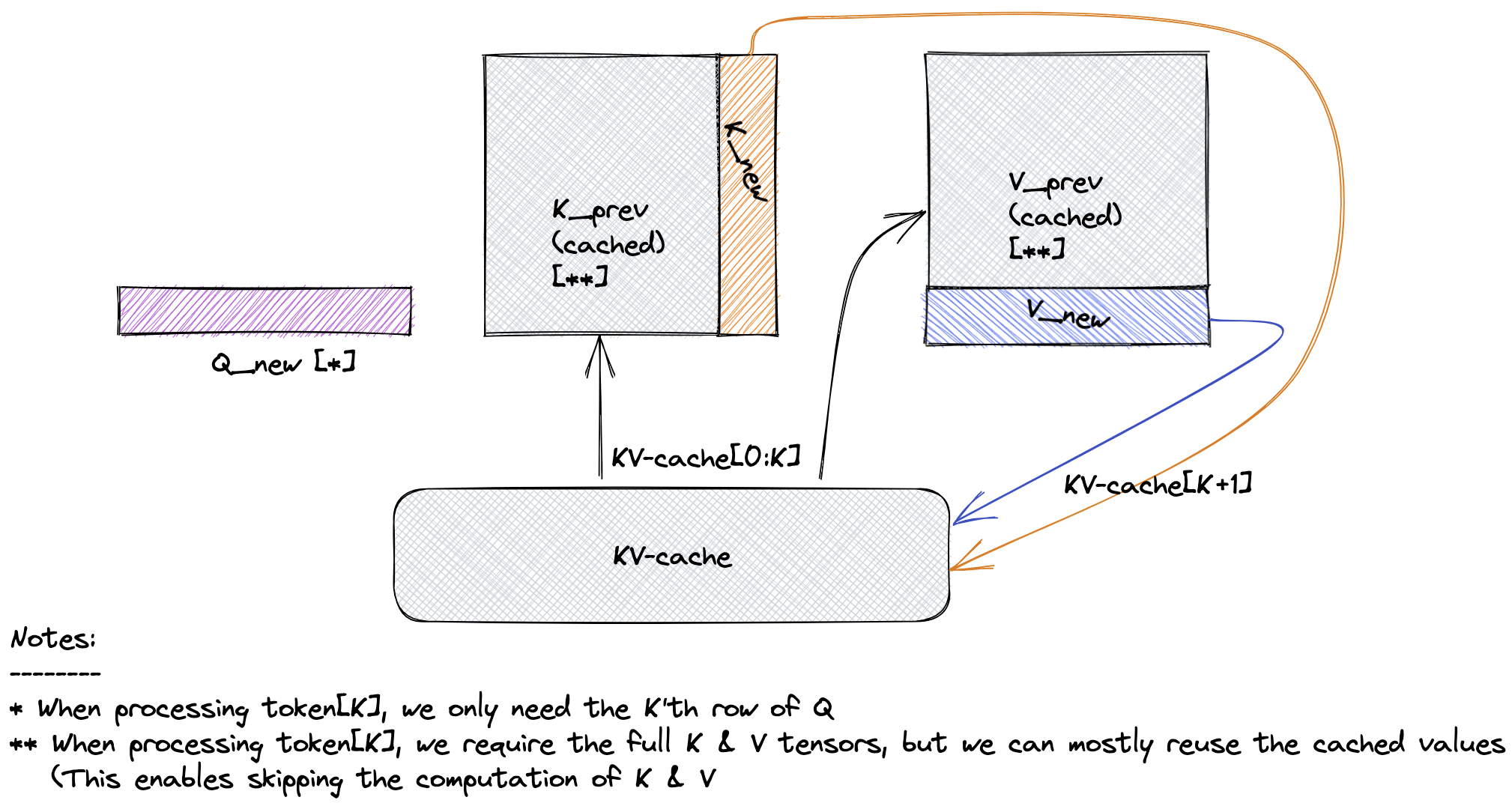
通过重用以前计算的 Self-Attention 键值对来节省计算资源,这种方式称之为 KV cache。
KV Cache 的内存占用
在长文本输入的情况下, KV chche 的占用是非常大的。
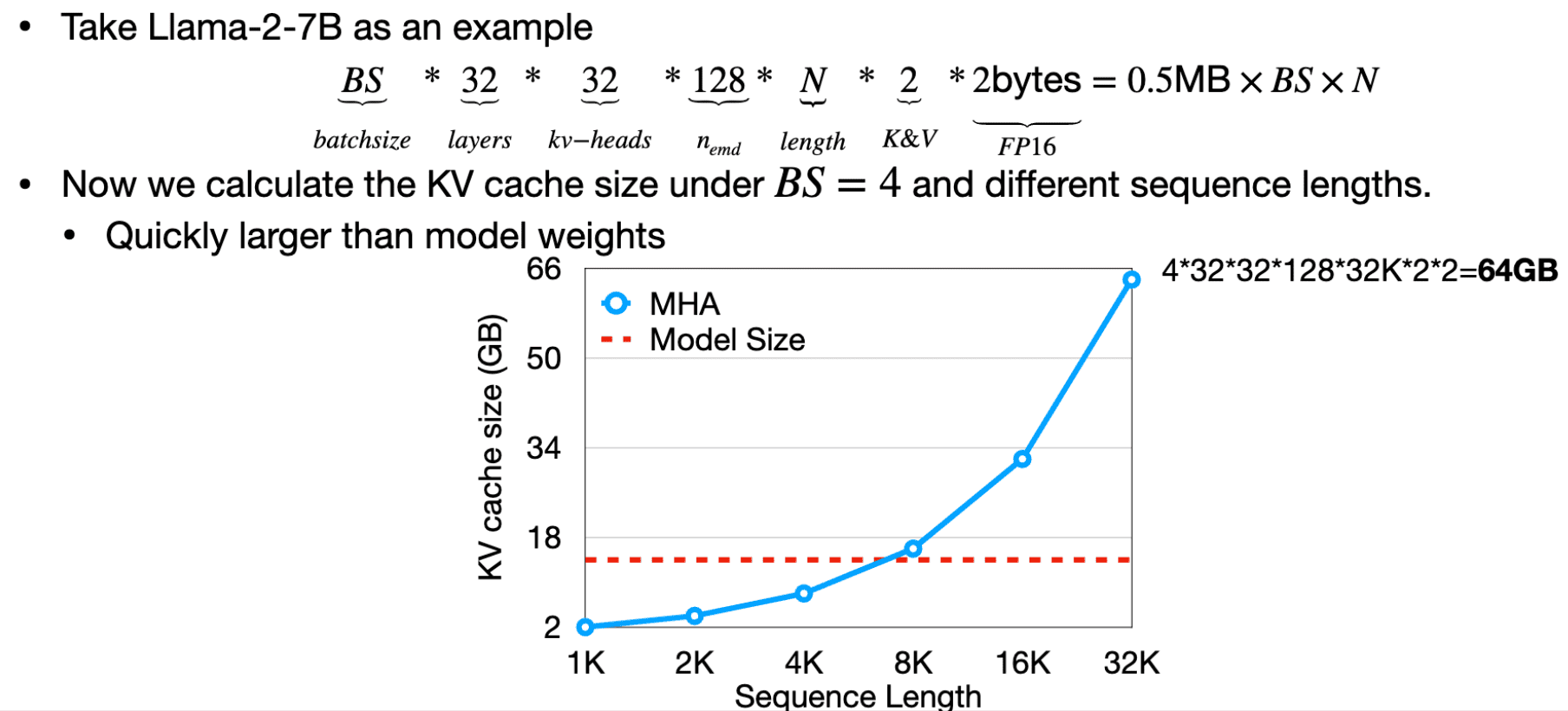
所以,防止内存不足必然是要使用 window attention,这样计算复杂度就变成了 O(TL).
The language model, pre-trained on texts of length L, predicts the Tth token (T ≫ L)
Window Attention
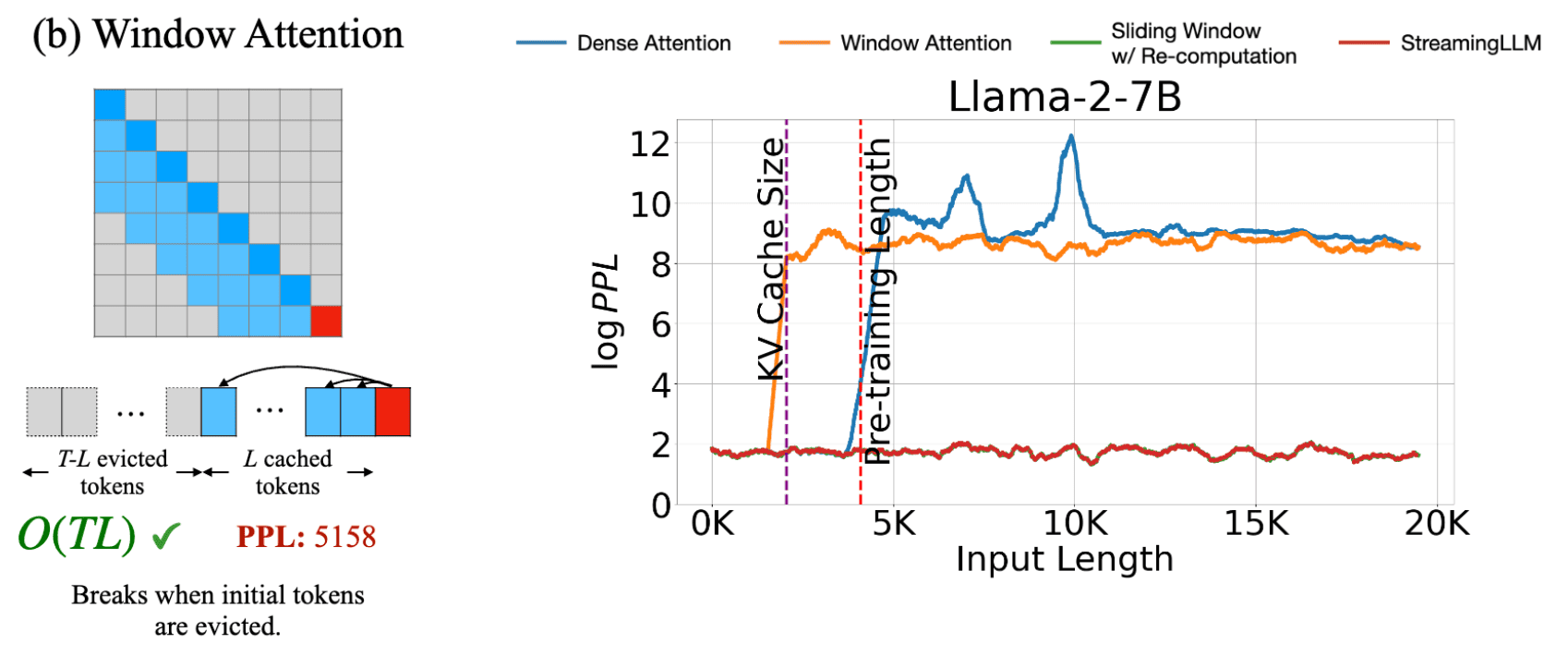
这种 window attention 的方法 cache 了最近 L 个 token 的KV,这样内存占用就很少了。问题是,一旦起始 token 的 KV cache 被逐出后,困惑度就爆炸了。
有趣的现象
为什么一旦起始 token 的 KV cache 被逐出后,困惑度就爆炸?因为第一个 token 非常重要
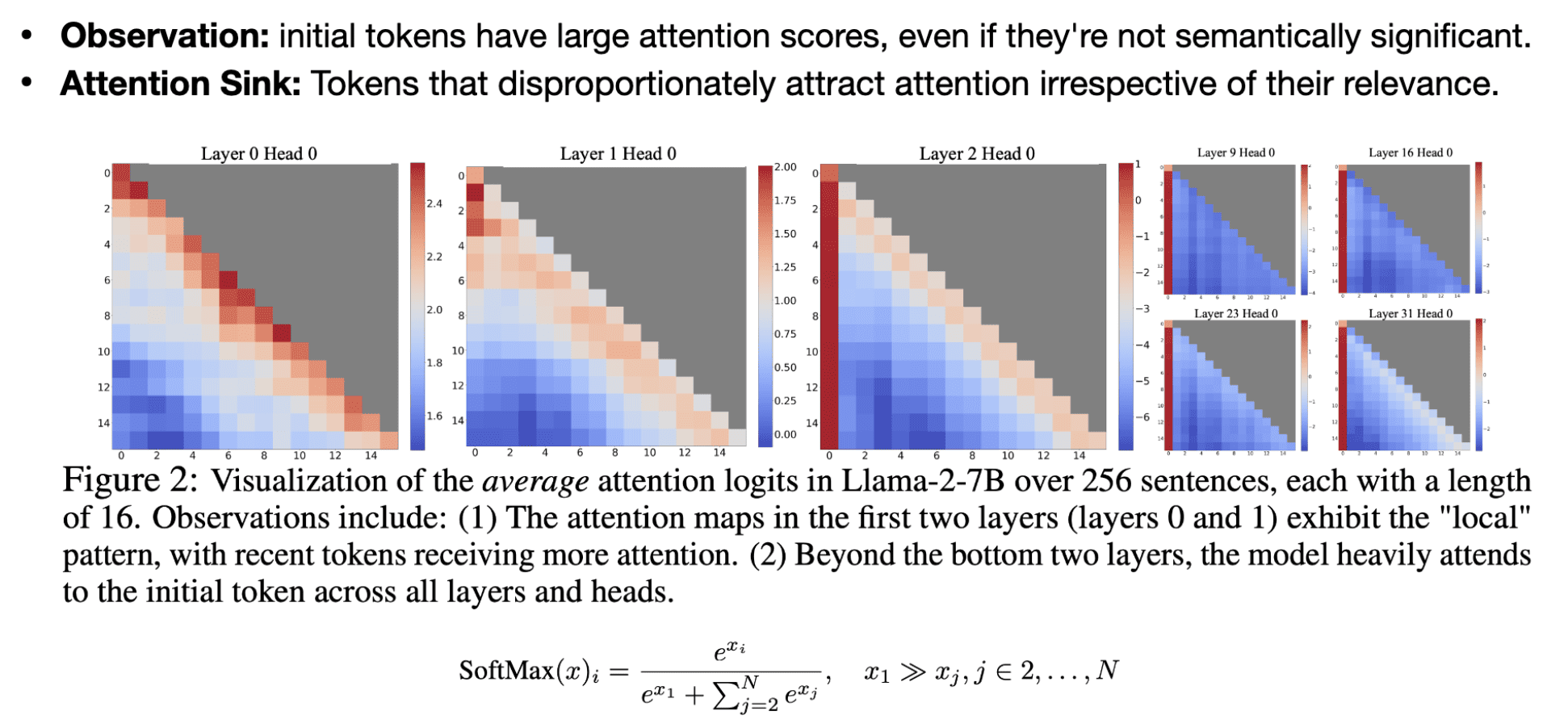
在第二层后,其他很多层的随机采样对第一个 token 有非常大的 attention,所以第一个token有很大的 attention score,即使这个token的语义没什么意义。
为什么会这样?这和 softmax 的原理有关系:

softmax必须是概率的总和为1,即使某些 token 不是那么的重要。
这就导致第一个 token 就很特别:由于是自回归的方式,所有后续的 token 都会关注第一个 token。
如果有些东西不是那么相关,就会把所有的 attention scores 转移到第一个 token。这就是所谓的 Attention sinks。
也就是说,模型过度关注初始的几个 token 是因为没有指定的 sink token 来 offload 过多的注意力分数。因此,该模型无意中使用全局可见的token(主要是 initial tokens)作为Attention sinks。
是位置重要还是语义重要?
实验证明,位置重要,前4个token的位置很重要。
解决方式
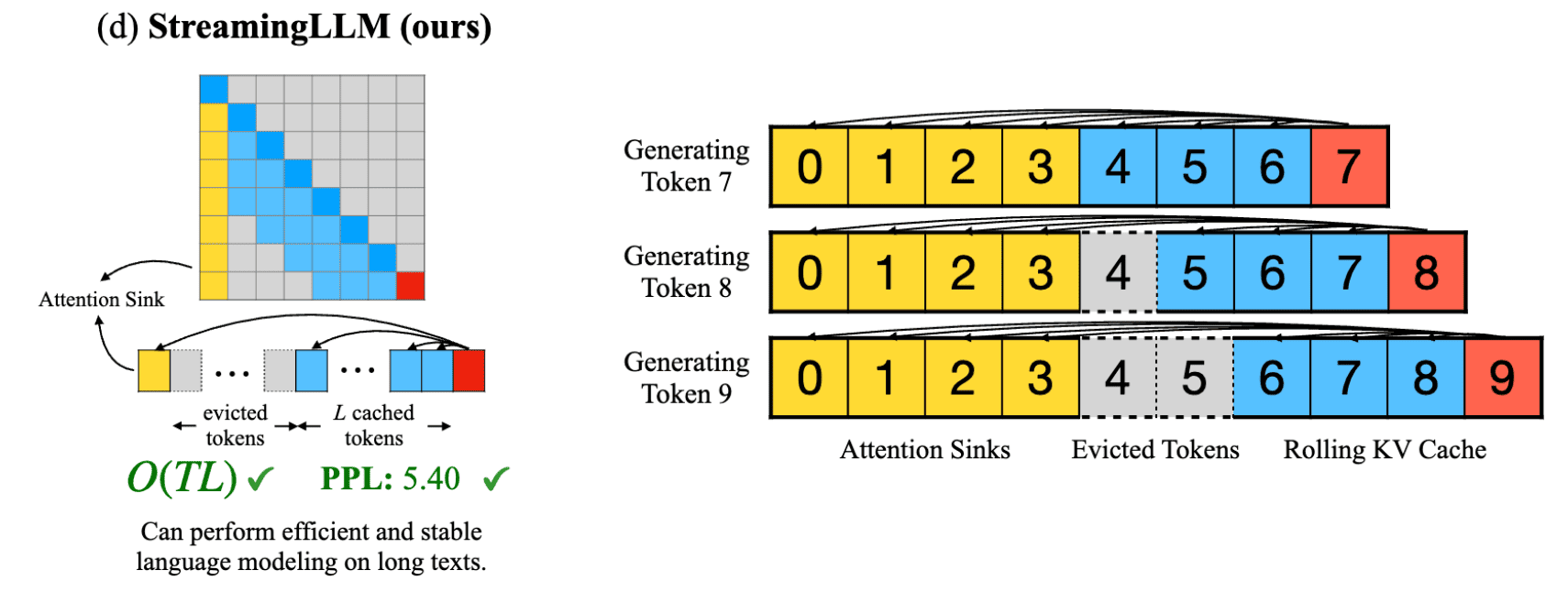
StreamingLLM 保留了 attention sink 也就是前几个 initial tokens, 这样就能进行稳定的 attention computation, 这几个attention sink 会与 最近的一些 tokens 共同组成一个 window。
就像图中,包含两部分
- Attention sinks (four initial tokens) stabilize the attention computation;
- Rolling KV Cache retains the most recent tokens, crucial for language modeling.
假设 KV cache 的大小是8,
- Generating Token 7
- 所有的都在KV Cache
- Generating Token 8
- 保留前四个Attention sinks,跳过4,使用 rolling window 的方式处理剩余的tokens
- 尤其需要注意这时候的 position encoding,这时候要使用 cache 里面的 position,而不是原始文本的 position。所以并不是[0,1,2,3,5,6,7,8],而是[0,1,2,3,4,5,6,7]
所以这种方式无需模型微调即可解决 window attention的困惑度问题。
StreamingLLM 与 Paged attention 集成
将第一页固定在 KV Cache 中,永远不 evicte KV Cache 的第一页。
-->会带来一点额外的开销。比如一个page有16个tokens,而你只需要固定4个tokens
总结
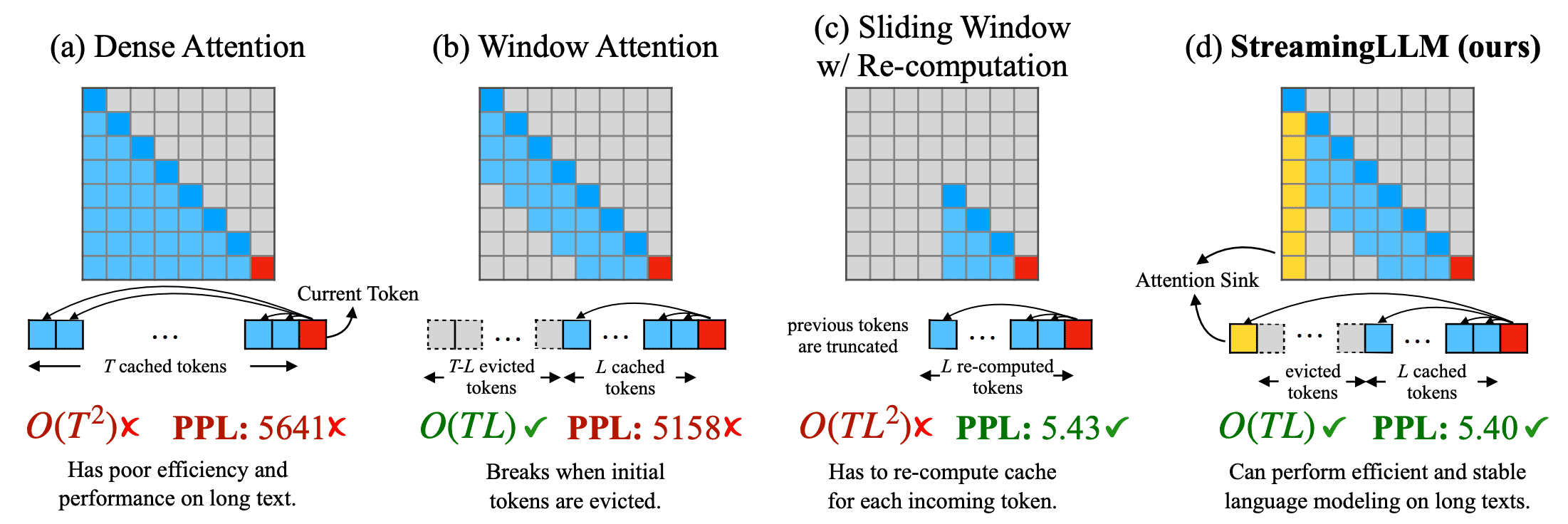
| 计算复杂度 | 困惑度 | 备注 | |
|---|---|---|---|
| Dense Attention | 高 O(T^2) | 差 | 输入长度如果超过训练时的上下文长度,困惑度就会爆炸。 |
| Window Attention | 低 O(TL) | 差 | 当句子长度超过窗口长度时,困惑度爆炸。 |
| Sliding Window Re-computation | 高 O(TL^2) | 优 | 计算量大 |
| StreamingLLM | 低 O(TL) | 优 |
代码研究
1 | pip install torch torchvision torchaudio |
Run Streaming Llama Chatbot
1 | CUDA_VISIBLE_DEVICES=0 python examples/run_streaming_llama.py --enable_streaming |
最开始没有注定安装transformers==4.33.0,遇到报错:
研究一下代码逻辑:
使用了默认的 model_name_or_path, lmsys/vicuna-13b-v1.3 下载到了
~/.cache/huggingface/transformers
data_root
start_size是4
recent_size是2000
在main函数里,load函数获取到 model 和 tokenizer。
Tokenizer 是 NLP 中的一个重要组件,负责将文本分解为更小的可处理单元。不同的分词策略适用于不同的语言和任务,选择合适的分词器对模型性能有很大影响。
由于使能了 enable_streaming
kv_cache = enable_streaming_llm(
model, start_size=args.start_size, recent_size=args.recent_size
)

