vLLM 支持 FP8(W8A8)了,开始学习fp8 ,写一个 FP8(W4A8)算子,减少一些IO吞吐,看看能不能提升性能。
官方文档
Using FP8 with Transformer Engine
视频 FP8 for Deep Learning 含有pdf
有价值的文章大模型量化技术原理:FP8
FP8 的好处
- Accelerates math-intensive operations(加速计算密集型操作)
- FP8 Tensor Cores are 2X faster than 16-bit Tensor Cores
- Accelerates memory-intensive operations(加速内存密集型操作)
- Reduces memory traffic, since 8-bits requires half number of bytes to access memory
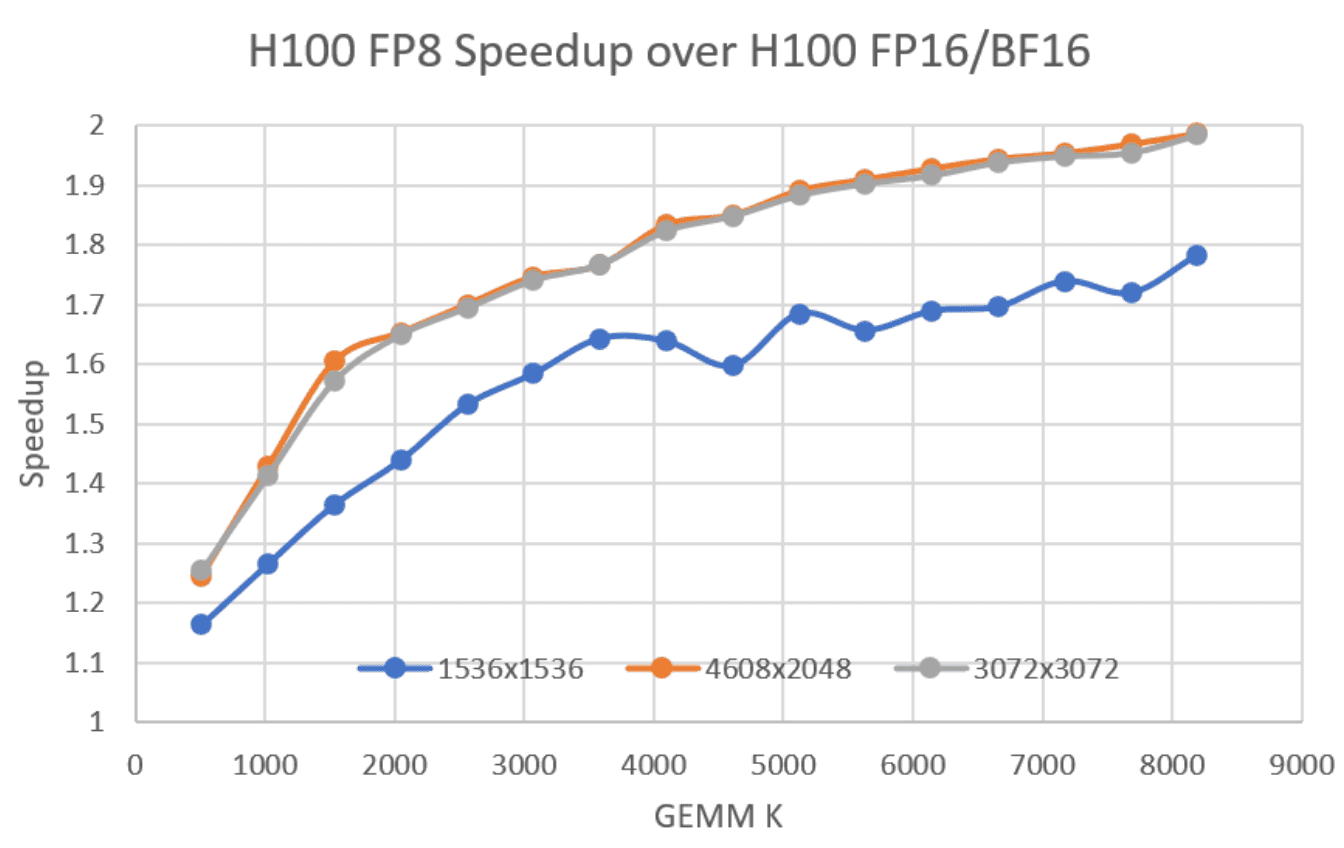
Note: Smaller GEMMs will achieve lower perf due to GPU underutilization, among other reasons

Performance improves as the K dimension increases, even when M=N is relatively large, as setup and tear-down overheads for the computation are amortized better when the dot product is longer. dl-performance-matrix-multiplication
FP8 数据类型
事实上,FP8(8-bit floating point) 数据类型分两种:
- E4M3
- it consists of 1 sign bit, 4 exponent bits and 3 bits of mantissa. (1 个符号位、4 个指数位和 3 位尾数)
- It can store values up to +/-448 and nan.(存储高至 +/-448 和 nan 的值,注意这个为了扩大动态范围,没有 inf)
- E5M2
- it consists of 1 sign bit, 5 exponent bits and 2 bits of mantissa. (1 个符号位、5 个指数位和 2 位尾数)
- It can store values up to +/-57344, +/- inf and nan. (存储高至 +/-57344、+/- inf 和 nan 的值)
- The tradeoff of the increased dynamic range is lower precision of the stored values.(增加动态范围的代价是存储值的精度较低)
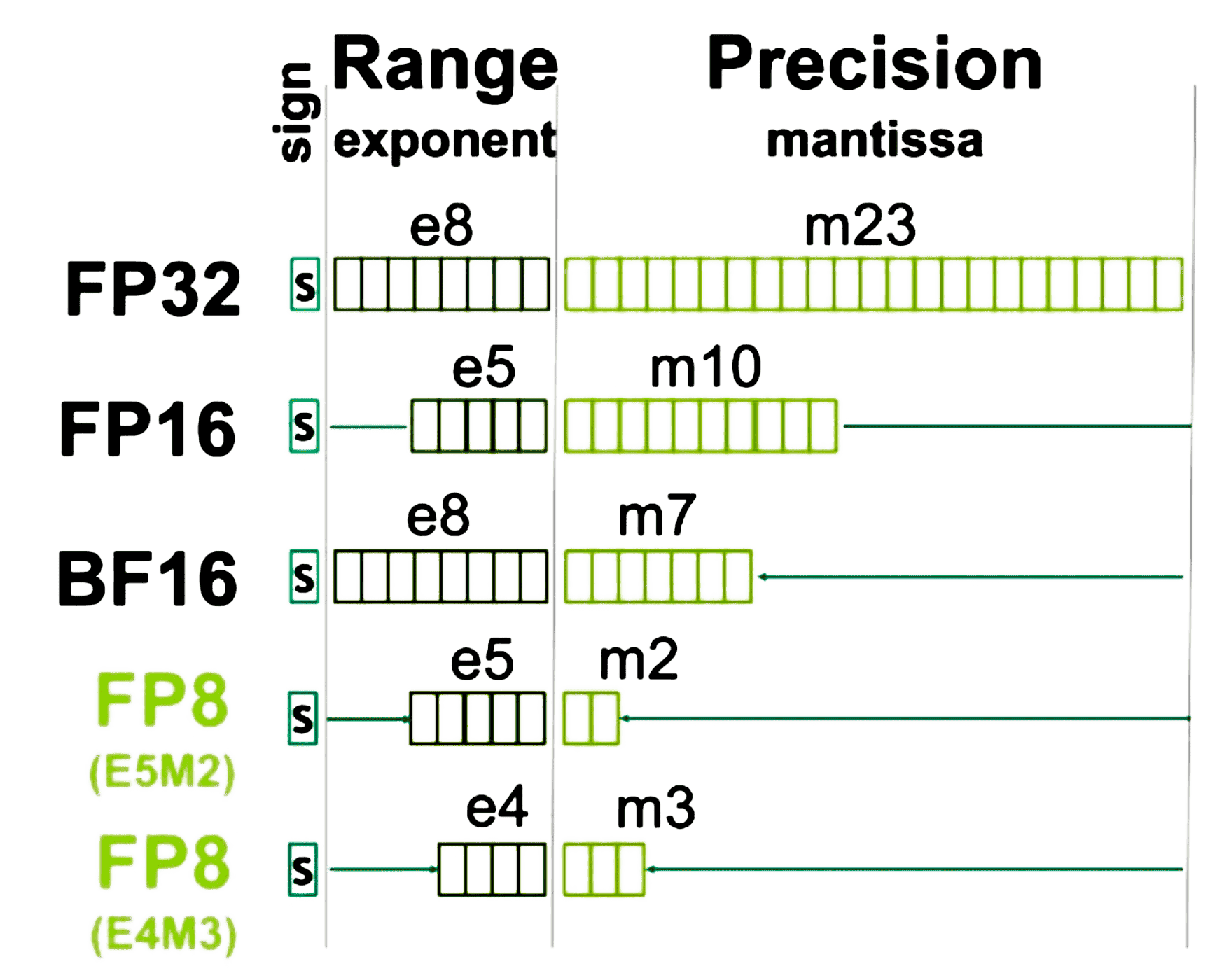
 浮点数据类型的结构。显示的所有值都是 0.3952 的最接近表示。
浮点数据类型的结构。显示的所有值都是 0.3952 的最接近表示。
在训练神经网络期间,可以使用这两种类型。
- 通常,前向激活和权重需要更高的精度,因此
E4M3数据类型最适合在前向传递期间使用。(2 位尾数对某些网络而言不够) - 然而,在后向传递中,流经网络的梯度通常不太容易受到精度损失的影响,但需要更高的动态范围。因此,最好使用
E5M2数据格式存储它们。 - H100 TensorCores 支持将这些类型的任意组合作为输入,使我们能够使用其首选精度存储每个张量。
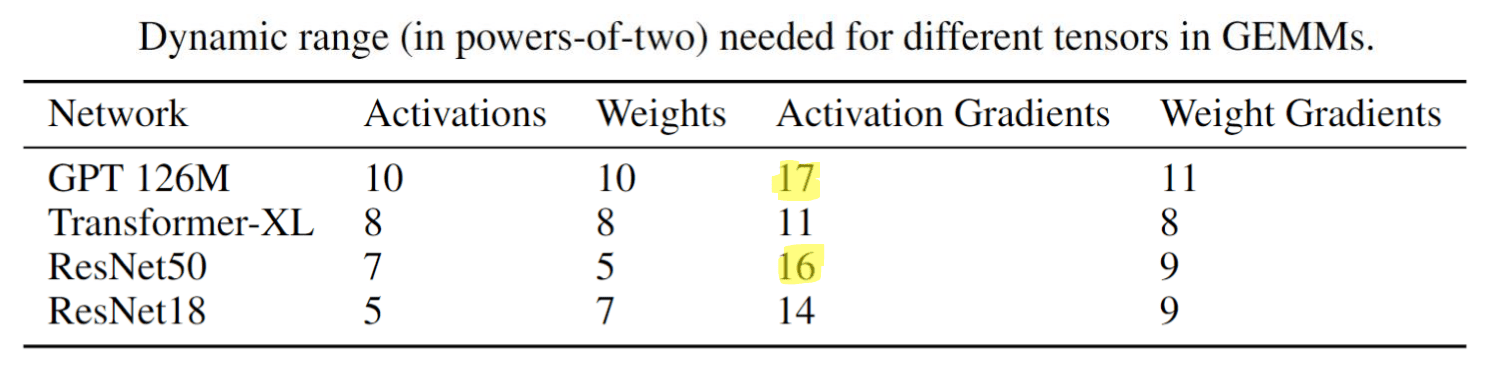
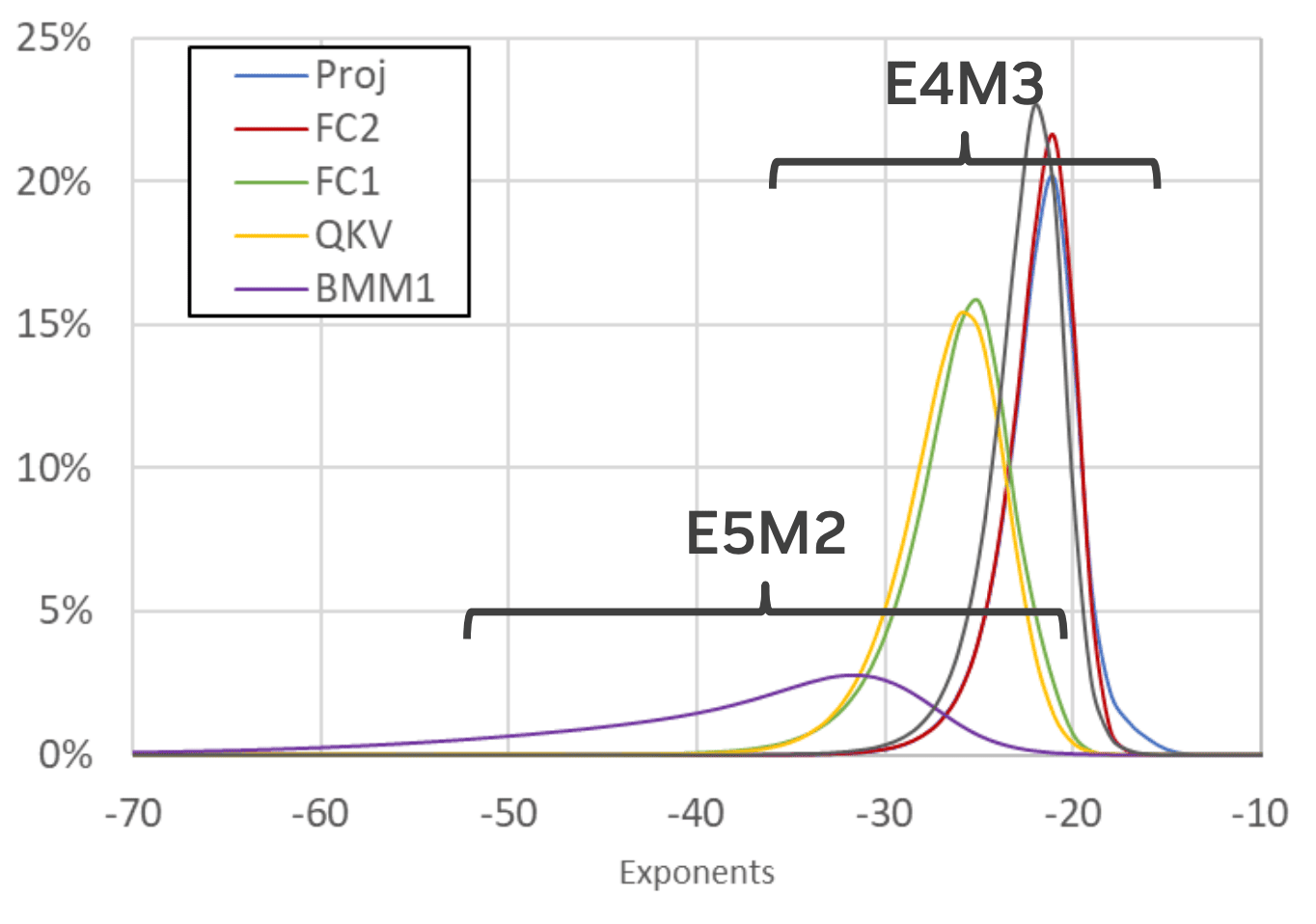
- E4M3 动态范围:2 的 18 次方
- E5M2 动态范围:2 的 32 次方
可以得出结论:A number of networks match higher-precision accuracy
with only E4M3。目标很明确了,我就使用 E4M3
的数据类型做推理。
E4M3 表示范围
参考论文 FP8 FORMATS FOR DEEP LEARNING
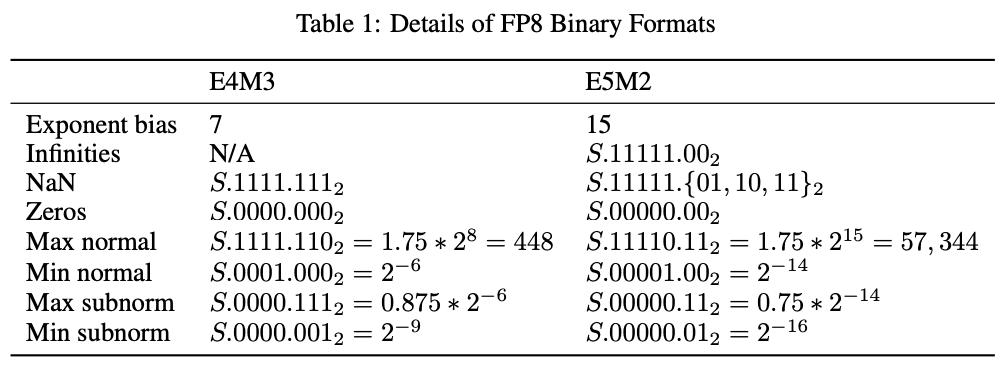
E4M3指数偏移量:7。实际的指数 e = E - 7 。
- 最小非零正数
当指数位
E = 1时(即存储的指数是0001),实际指数e = 1 - 7 = -6。尾数
M = 0时,隐含的有效位为1,所以最小的非零正数是1.0 * 2^{-6} = 2^{-6},即:2^{-6} = 0.015625次正规数(Subnormal numbers):当
E = 0时,指数固定为e = -6,但尾数不再隐含有效位 1,因此最小的次正规数为0.125 * 2^{-6}即:0.125 * 2^{-6} = 0.001953125在正规数中,尾数有隐含的 1.,而次正规数没有隐含的 1.,因此可以表示更小的数。 次正规数的引入是为了避免在计算非常小的数时直接舍入为 0,保持一定的精度。
- 最大值
FP8 (E4M3) 最大指数
E = 15(即存储的指数是 1111,本来这种是inf的),表示指数e = 8,最大值是:1.75 * 2^8 = 448因此,FP8 E4M3 能表示的最大值为 ±448。
- 特殊值
- NaN(非数字):当指数 E = 15 且尾数 M ≠ 0 时,表示 NaN(Not a Number)。
- 没有无穷大 (Inf):E4M3 格式无法表示正负无穷大,当指数位 E = 1111 且尾数为 0 时,不表示无穷大,而是最大值 448。
综上,FP8 (E4M3) 的数值表示范围
- 最小次正规数: 0.001953125 。
- 最小非零正规数: 0.015625 。
- 最大值:±448。
- NaN:当指数全为 1 且尾数不为 0 时表示 NaN(非数字)。
Tensor Cores
在Tensor Cores中使用FP8数据类型进行矩阵乘法运算
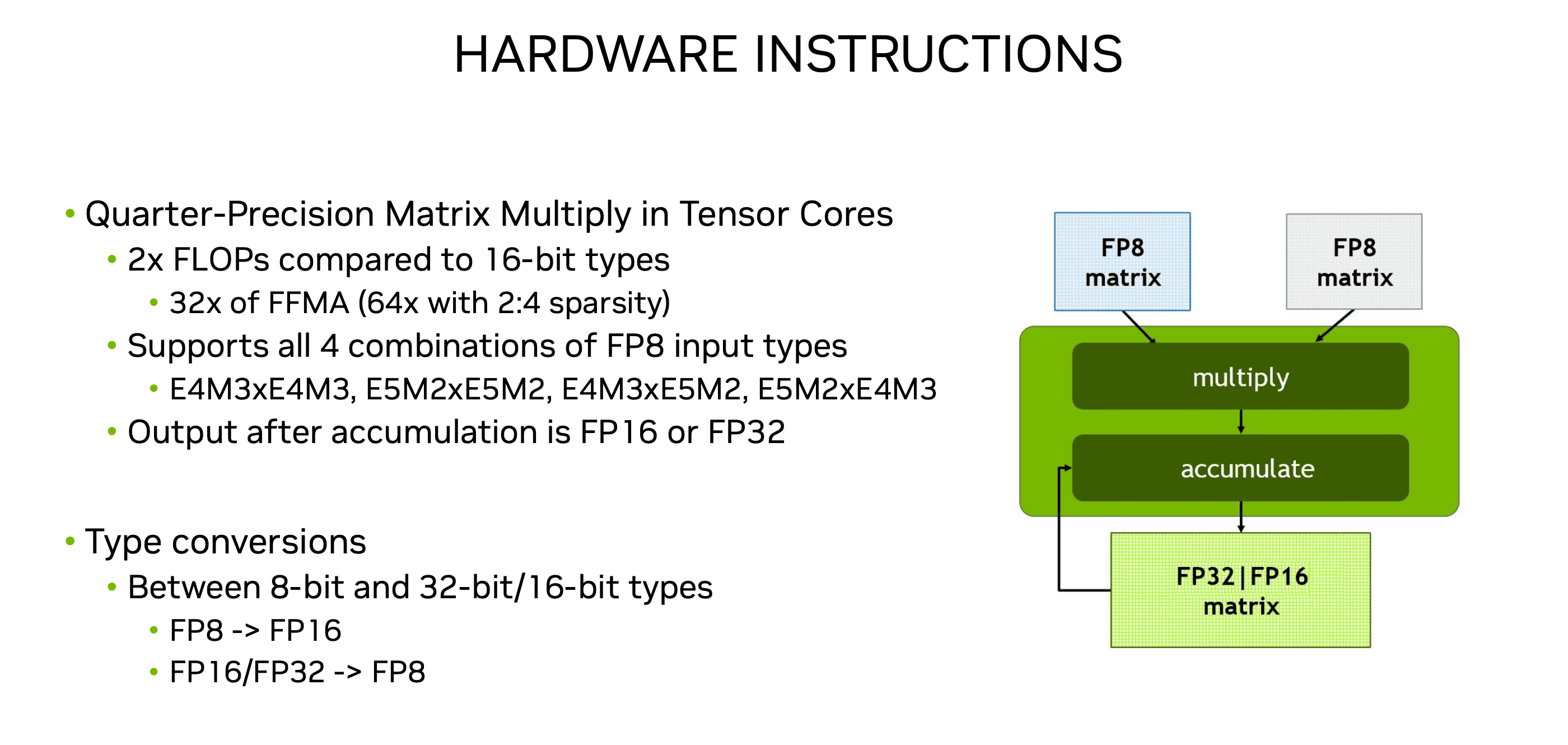
- 相比于16位的数据类型,2倍的FLOP(浮点运算次数)
- FFMA(Fuse Multiply-Add,融合乘加)操作可以达到 32倍的计算效率,在使用2:4稀疏性(sparsity)时,这个倍率可以提升到 64倍
- 支持所有FP8输入类型的组合
- 操作之后的输出可以是 FP16(16位浮点数)或者 FP32(32位浮点数)
- 支持在 8位和32位/16位数据类型 之间的转换。
FP8 for DL
What’s needed for inference numerics
- Per-tensor scaling
- Mixed precision
What’s needed for performance (speed):
- FP8 Tensor Cores, for faster math
- FP8 I/O, to reduce bandwidth pressure
Per-tensor scaling
FP8 的动态范围往往比较窄,这导致无法单纯用 FP8 表示神经网络中所有的数值。
FP8 往往对 给定张量 具有足够的范围,但并不总是对所有张量都具有足够的范围,因此每个张量都进行缩放。
张量值以更高精度计算,在转换为 FP8 之前进行 scale。核心思想就是使用 scale 将每个 tensor 的数值范围适应 FP8 的表示范围。
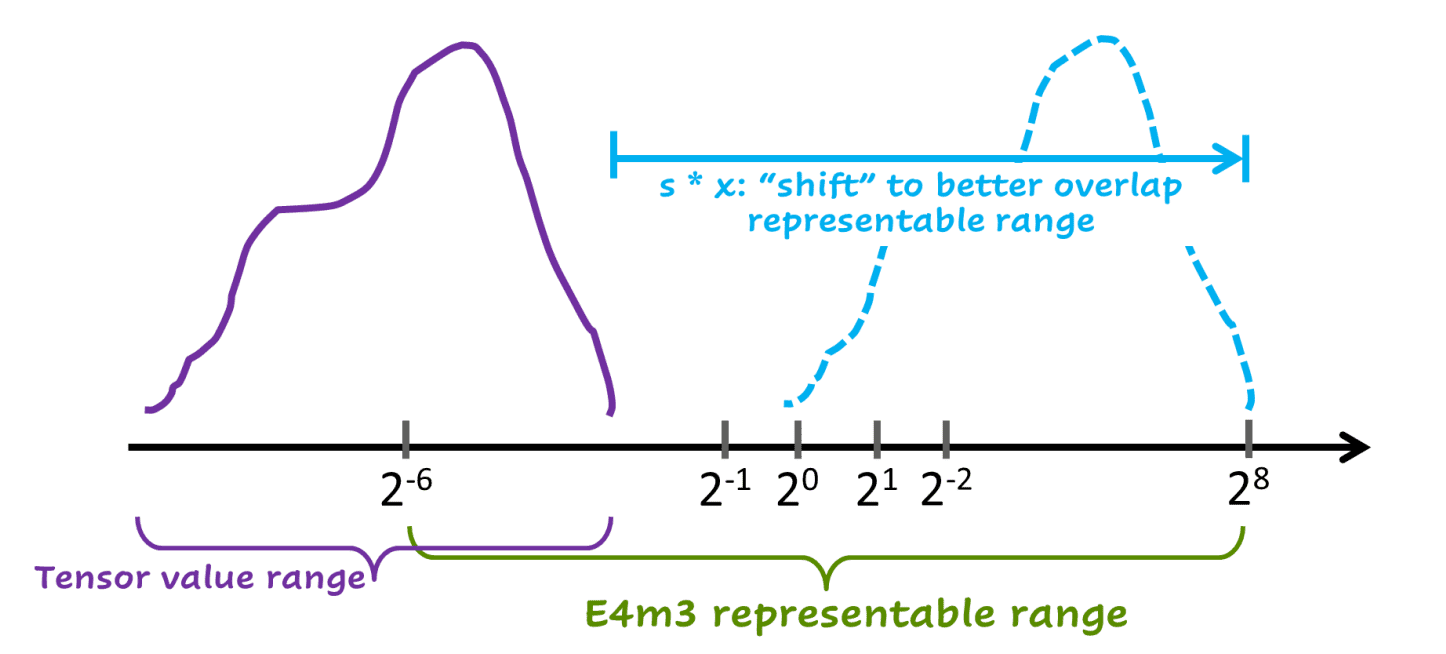
就像上图,紫色的曲线代表原始tensor的表示范围,几乎有一半都在 FP8 的表示范围以外,导致小于 2^(-6) 的数都变成了0。
使用 scale因子 S,使得数据分布向右移动,这条蓝色虚线曲线就全部在 FP8 的表示范围内。
整体目标
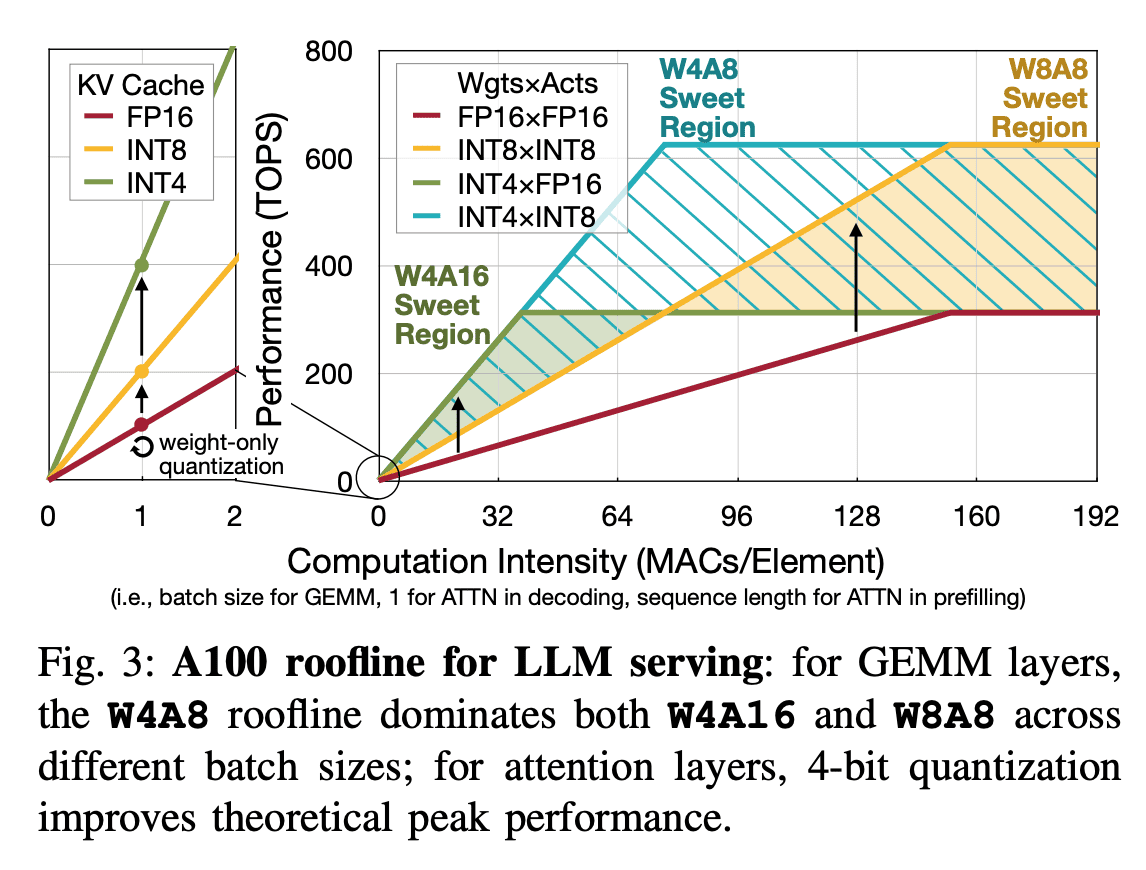
QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving论文中这个图比较明显的展示出了不同数据类型(FP16、INT8、INT4等)在不同计算密度下的性能表现,即A100的roofline模型。
- 在计算密度较低的区域是 W4A16 / W4A8(int8) Sweet Region
- 在计算密度较高的区域是 W8A8 Sweet Region
目标就是 W4A8(fp8),即能有好的推理性能,又能有比W4A8(int8)更好的精度性能。
- 2024.10.21
实验
实验平台:NVIDIA L40 是基于 Ada Lovelace 架构的一款高端数据中心和工作站级 GPU。
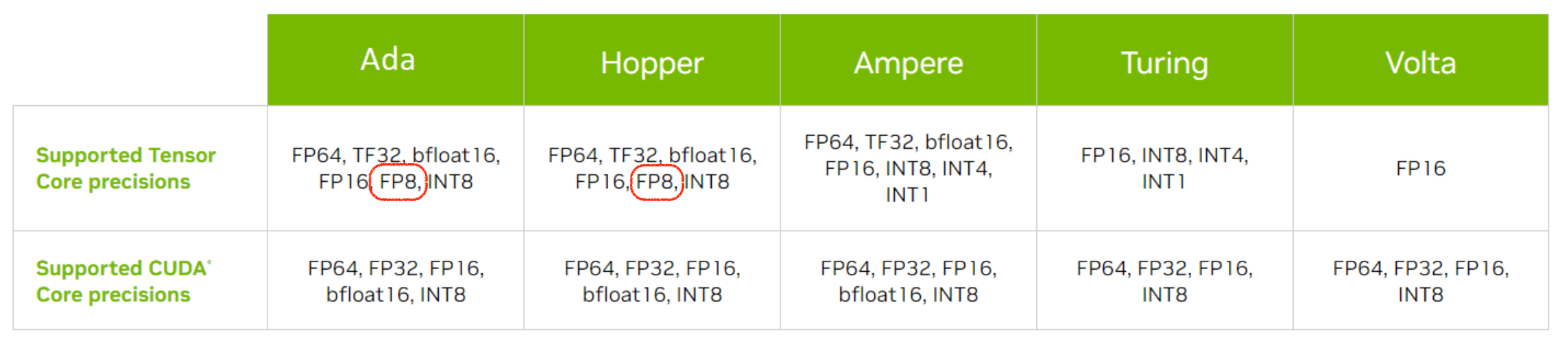
Nvidia L40 GPU硬件参数如下,可以发现FP8 Tensor Core和INT8 Tensor Core在各自数据类型上的计算能力是相同的

思路:巧用符号位!
一个INT4数字只能精确表示从-8到7的16个整数。
2024.10.24 在程序员节这天想出了int4转fp8的好方法!
问题卡在如何实现类似于 __hsub2 的 fp8
的向量化减法函数
在C++ struct for handling vector type of four fp8 values of e4m3 kind.也没有找到相关函数。
去论坛问了一下:Handling vector type of four fp8 values Arithmetic Functions
学习CUTLASS 半小时快速入门CUTLASS
CUTLASS中include/cutlass/arch/mma_sm89.h中
Matrix Multiply 16832 - Float {E4M3, E5M2}, FP32 accumulation
Matrix multiply-add operation - F32 = fe4m3 * fe4m3 + F32
在L40
运行cutlass,./exampless/58_ada_fp8_gemm/58_ada_fp8_gemm
Running GEMM with staged accumulation (OpMultiplyAdd)
=====================
Skipped reference check
Problem size: 1024x1024x1024
Runtime (ms): 0.0117968
GFLOPs/sec: 182040
Passed
Running GEMM with fast accumulation (OpMultiplyAddFastAccum)
=====================
Skipped reference check
Problem size: 1024x1024x1024
Runtime (ms): 0.0110768
GFLOPs/sec: 193872
PassedL40最大是 362
QQQ的思路是
W4A8版本的Kernel输入输出与W4A16版本的输入输出有一些区别:
A: 数据类型为int8_t,W4A16版本为fp16。
C: 是额外添加的专门用来做global_reduce的buffer。W4A16版本以输出C矩阵作为buffer来进行global_reduce。由于int8 Tensor Core的计算结果是int32_t,与输出结果(fp16)数据类型不同,因此额外开辟了一块全局显存来做global_reduce。
D:输出结果。
s1: activation的per_channel scale。
s2: 权重的per_channel scale。
s3: 权重的per_group scale。
当权重做per_channel量化时,s3为空。当权重做per_group量化时,权重有两个scale:s2(per_channel)和s3(per_group)。这和量化算法相关
而这里A搞改成fp8,C不用改


