This project records the process of optimizing SGEMM (single-precision floating point General Matrix Multiplication) on the riscv platform.
This project records the process of optimizing SGEMM (single-precision floating point General Matrix Multiplication) on the riscv platform.
General Matrix Multiplication (GEMM) is one of the core computing units in deep learning frameworks, widely used for implementing operators such as Convolution, Full Connection, and Matmul.
I conducted experiments and explorations on the Allwinner
Nezha D1 development board. Versions 0 through 5
were implemented using the C language, while
versions 6 through 9 partially utilized assembly language,
involving the RISC-V V extension instructions.
Note: Unlike some other GEMM optimization projects, this project uses row-major order matrices exclusively. Because I prefer row-major order!
Prerequisite Knowledge

RISC-V is an open standard Instruction Set Architecture (ISA) enabling a new era of processor innovation through open collaboration.
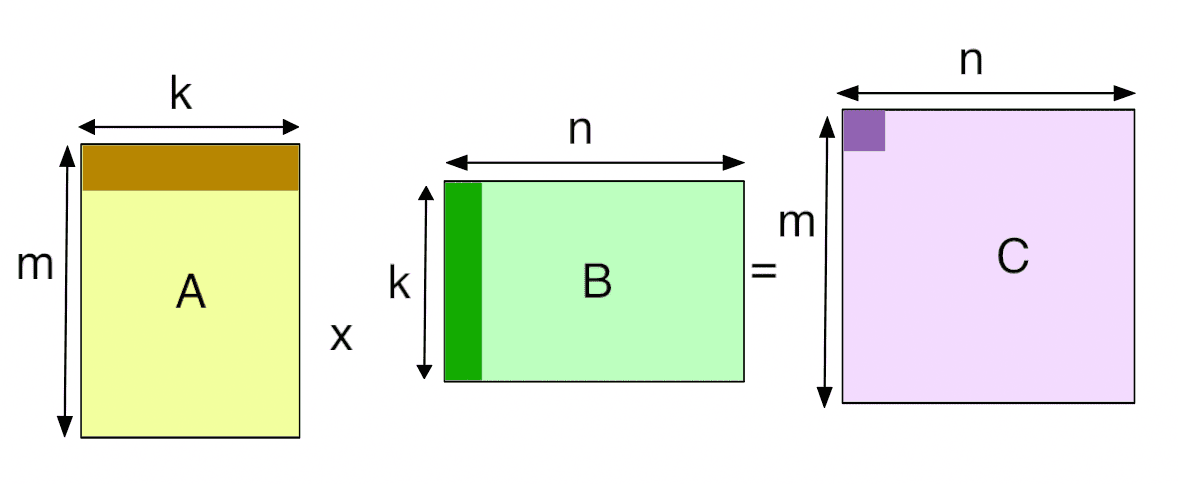
GEMM General matrix multiply, one of the Basic Linear Algebra Subprograms.
FLOPS stands for Floating-point Operations Per Second, also known as peak speed per second. It refers to the number of floating-point operations executed per second. One gigaflop (GFLOPS) equals ten to the power of nine (10^9) floating-point operations per second.
The computational complexity of matrix multiplication is calculated
as 2 * M * N * K. The ratio of computational complexity to
time taken gives the GFLOPS of the current GEMM version. - Multiplying
by 2 is because each operation involves one multiplication and one
addition.
Prepare
The related code is located in ./prepare/.
Test Cross-Compilation
I use the Allwinner Nezha D1 development board, and downloaded the cross-compilation link from here.
For detailed instructions, please refer to the readme.
Memory Bandwidth Test
I conducted memory bandwidth tests on the development board using the following projects:

Roofline Model
Roofline proposes a method for quantitative analysis using "Operational Intensity" and provides a formula for the theoretical performance limit achievable on computational platforms.
According to OpenPPL Public Course | RISC-V Technical Analysis:
- The computing power of D1 can reach
4 GFlops(@1GHz). - Memory:
2.727 GB/s(DDR3 792 MHz).- Although I measured the highest as
2.592 GB/s, there may be some problems somewhere? - Let's trust Sensetime for now, temporarily accept its value.
- Although I measured the highest as
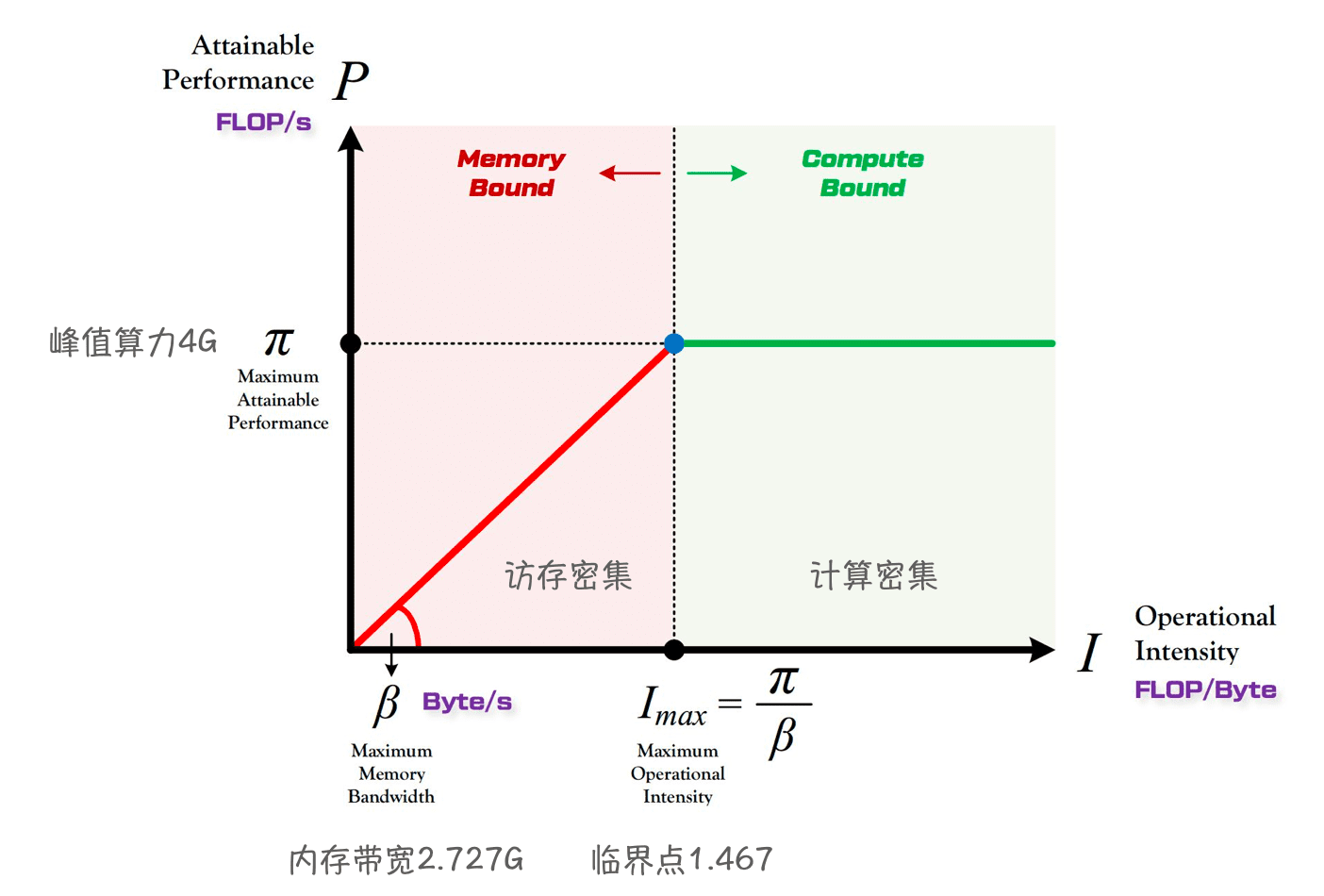
SGEMM Optimization
Related code is located in ./sgemm/.
Usage
Take step0 as an example, you need to edit the Makefile
first to configure your cross-compilation chain.
1 | cd sgemm/step0/ |
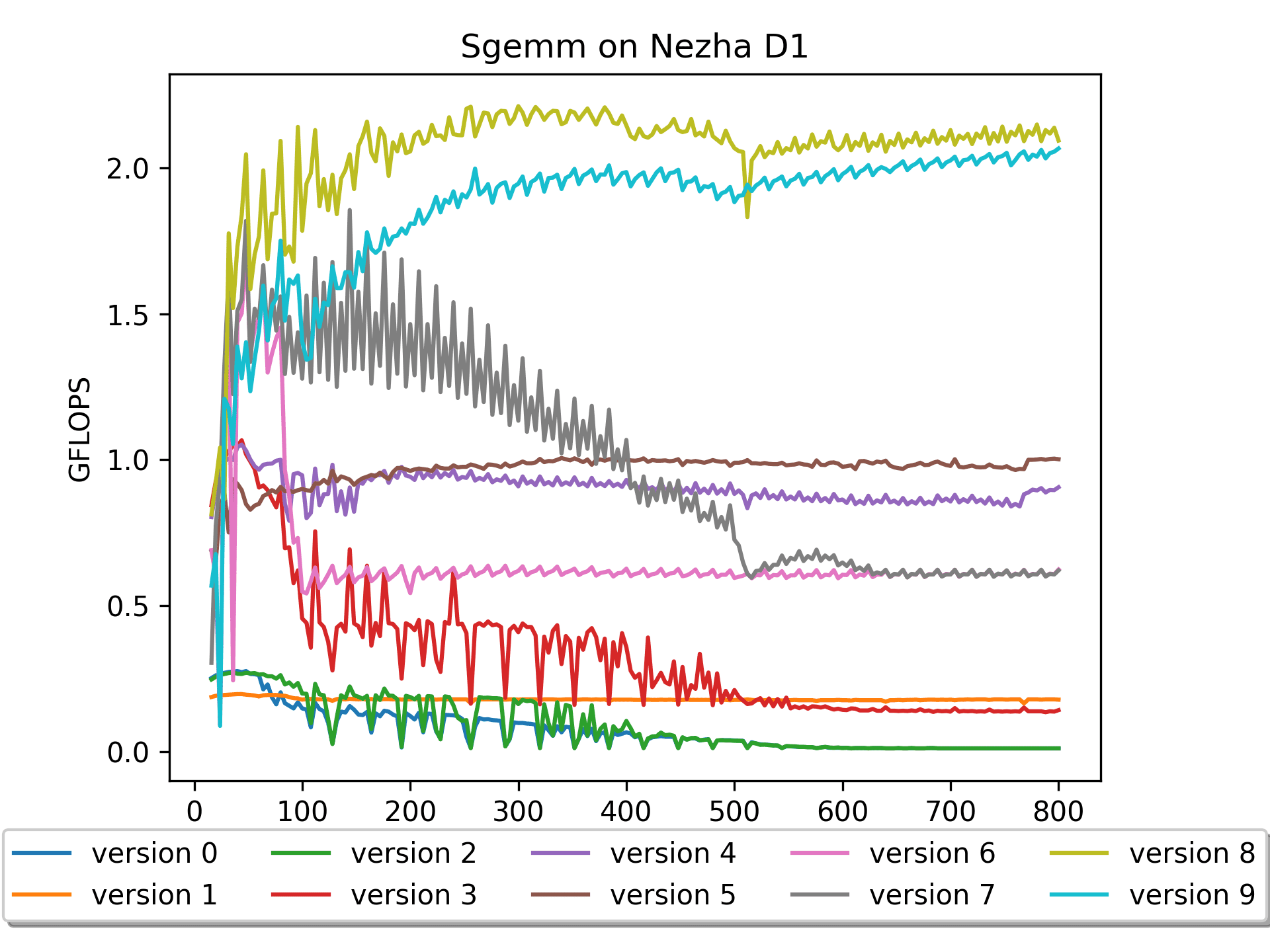
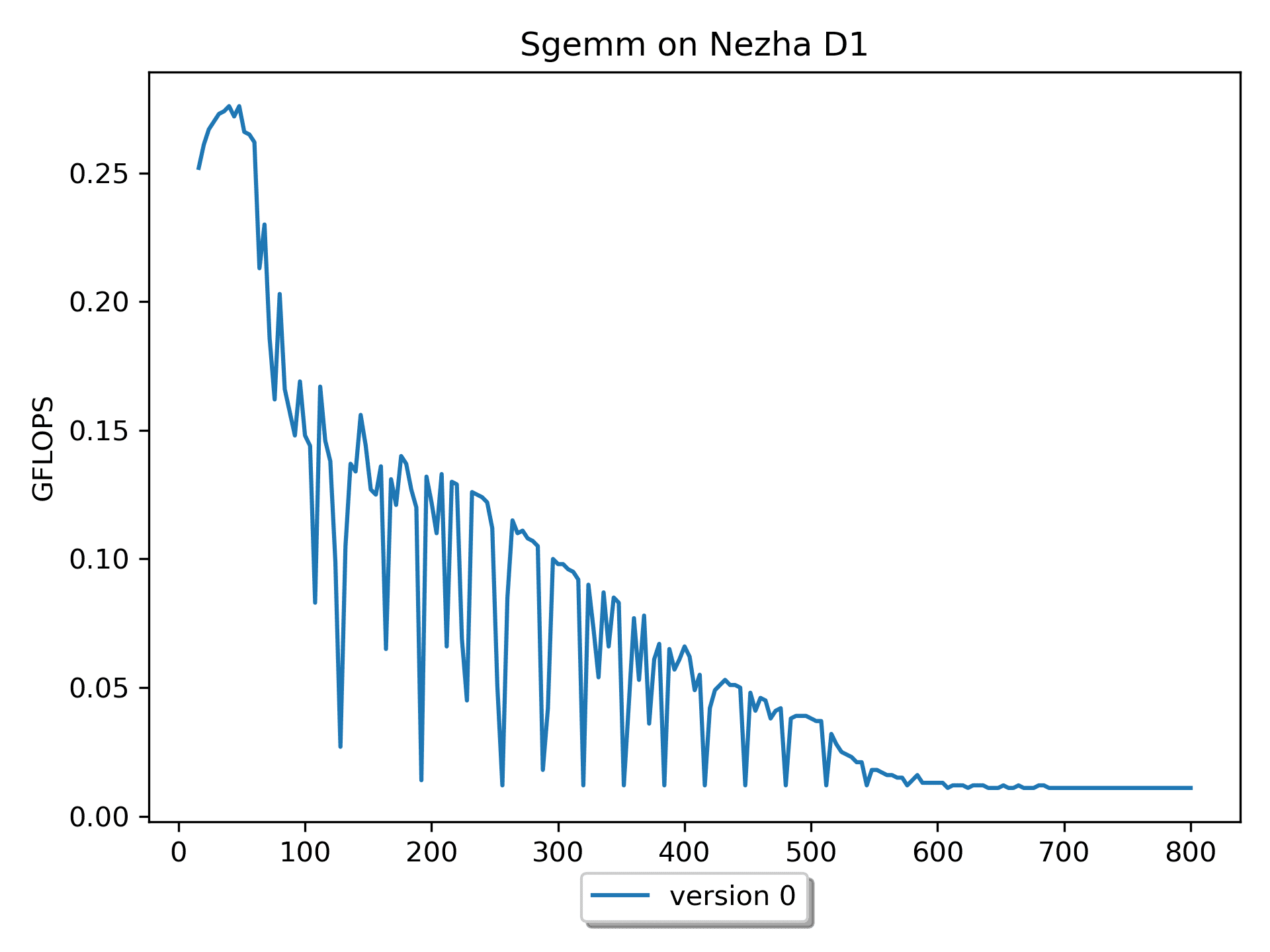
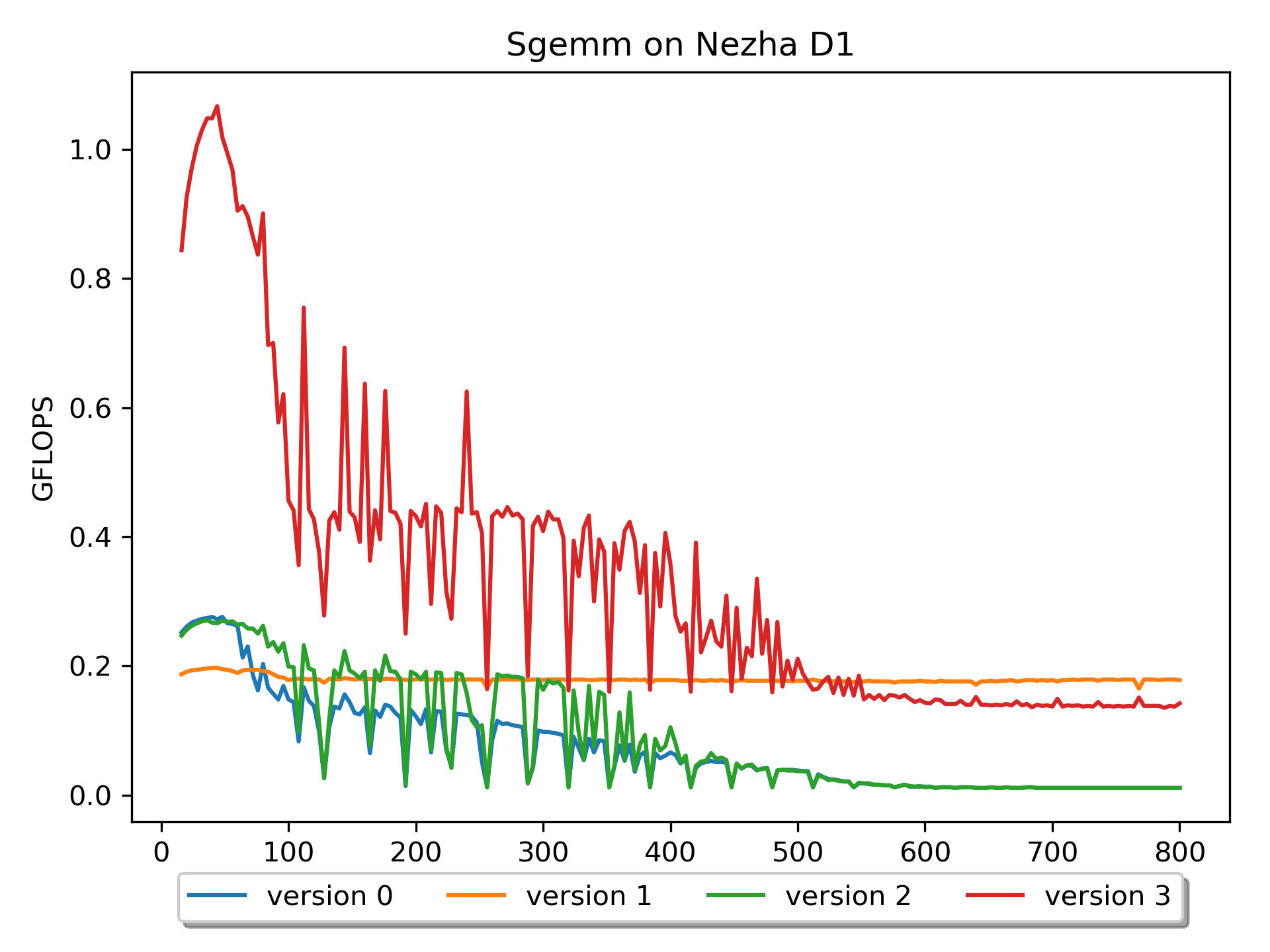
Version 0: Naive Version
This version seems to be the most intuitive to me, after all, this is how I learned, understood, and computed matrix multiplication: > Multiply one row of A by one column of B to get one element of C.
1 | for ( i = 0; i < m; i ++ ) { // Start 2-th loop |
I think version 0 very well explains the formula \(C_{mn} = \sum_{k=1}^{K} A_{mk}B_{kn}\).
However, this version has obvious shortcomings: on a platform with a
theoretical computing power of 4 GFLOPS, it only achieves a
maximum computational performance of 0.03 GFLOPS. This is
because the access to matrix B has a very low cache hit rate,
i.e., "poor spatial locality". Throughout the calculation, it
is equivalent to accessing matrix B many, many times.
It is advisable to access the elements of multi-dimensional arrays in sequential order. This can improve the spatial locality of memory access and make it more friendly to the cache.
Furthermore, it can be observed that with the increase in size, the performance fluctuates significantly. Analysis of the data shows that when m=n=k is 128 164 192 228 256 288 320 352 384, the performance is poor. These numbers differ by 32, and 32 * 4 (sizeof(float)) = 128 B.
It is speculated that the performance fluctuation is related to cacheline and hardware prefetching -- cacheline = 64B, after cache miss, hardware prefetching, i.e., HWPrefetcher, reads one more cacheline.
Version 1: Loop Interchange Version
Reusing data in the cache is the most basic and efficient use of
cache. For nested loops, loop interchange,
loop reversal, loop fusion,
loop distribution, loop tiling,
loop unrolling and jam, etc., can be used to improve
program performance.
Selecting an appropriate loop transformation method can both maintain the semantics of the program and improve its performance.
1 | for ( i = 0; i < m; i ++ ) { // Start 2-th loop |
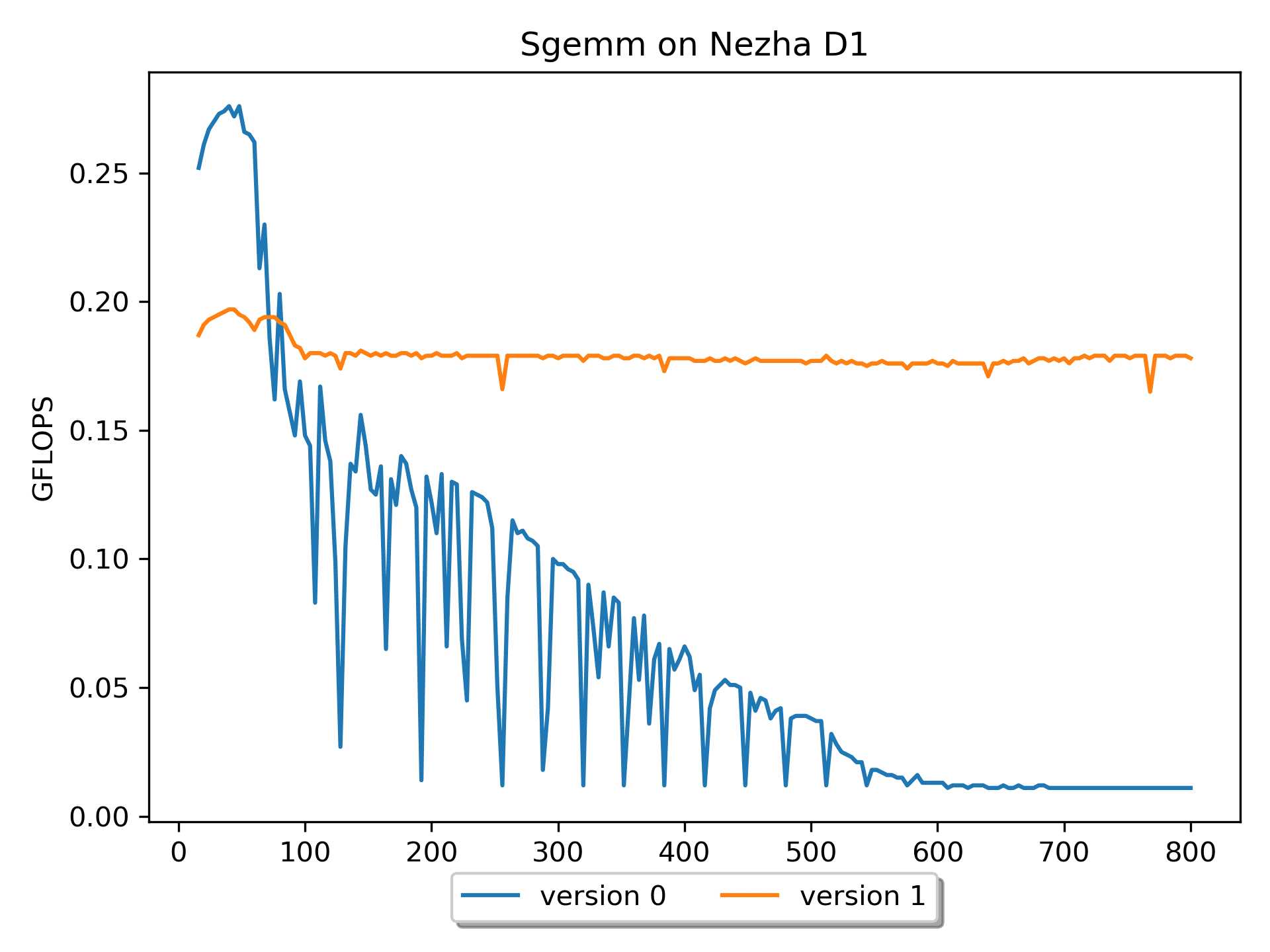
Compared with version 0, version 1 has
better spatial locality for the operation on matrix B, and the
performance has been greatly improved (especially for larger sizes,
while for m = n = k <= 68, the efficiency of version 0 is
higher).
Adjusting the order of m, n, and k does not affect the result (i.e., maintaining the semantics of the program), but it can affect the performance. Testing the performance of different loop orders (using the Allwinner Nezha D1 platform, with m=n=k=512 as an example)
| Loop Order | GFLOPS | Analysis |
|---|---|---|
| MNK | 0.012 | High cache miss for accessing B |
| MKN | 0.180 | |
| NMK | 0.012 | High cache miss for accessing B |
| NKM | 0.009 | High cache miss for accessing A |
| KMN | 0.165 | |
| KNM | 0.009 | High cache miss for accessing A |
However, the hardware utilization of version 1 is still
very low, and further optimizations are needed.
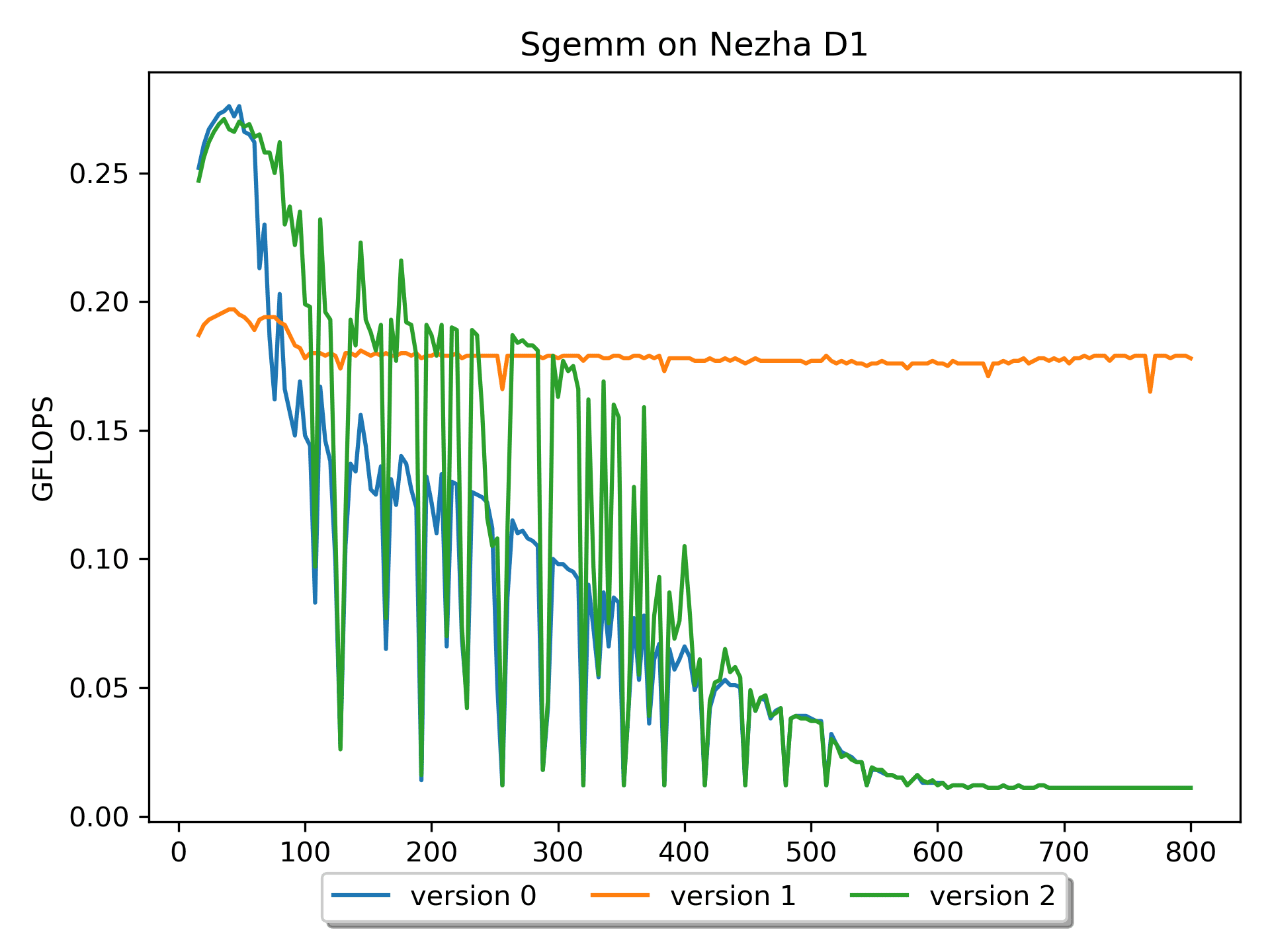
Version 2: Blocking Version
1 | for ( i = 0; i < m; i += DGEMM_MR ) { // Start 2-nd loop |
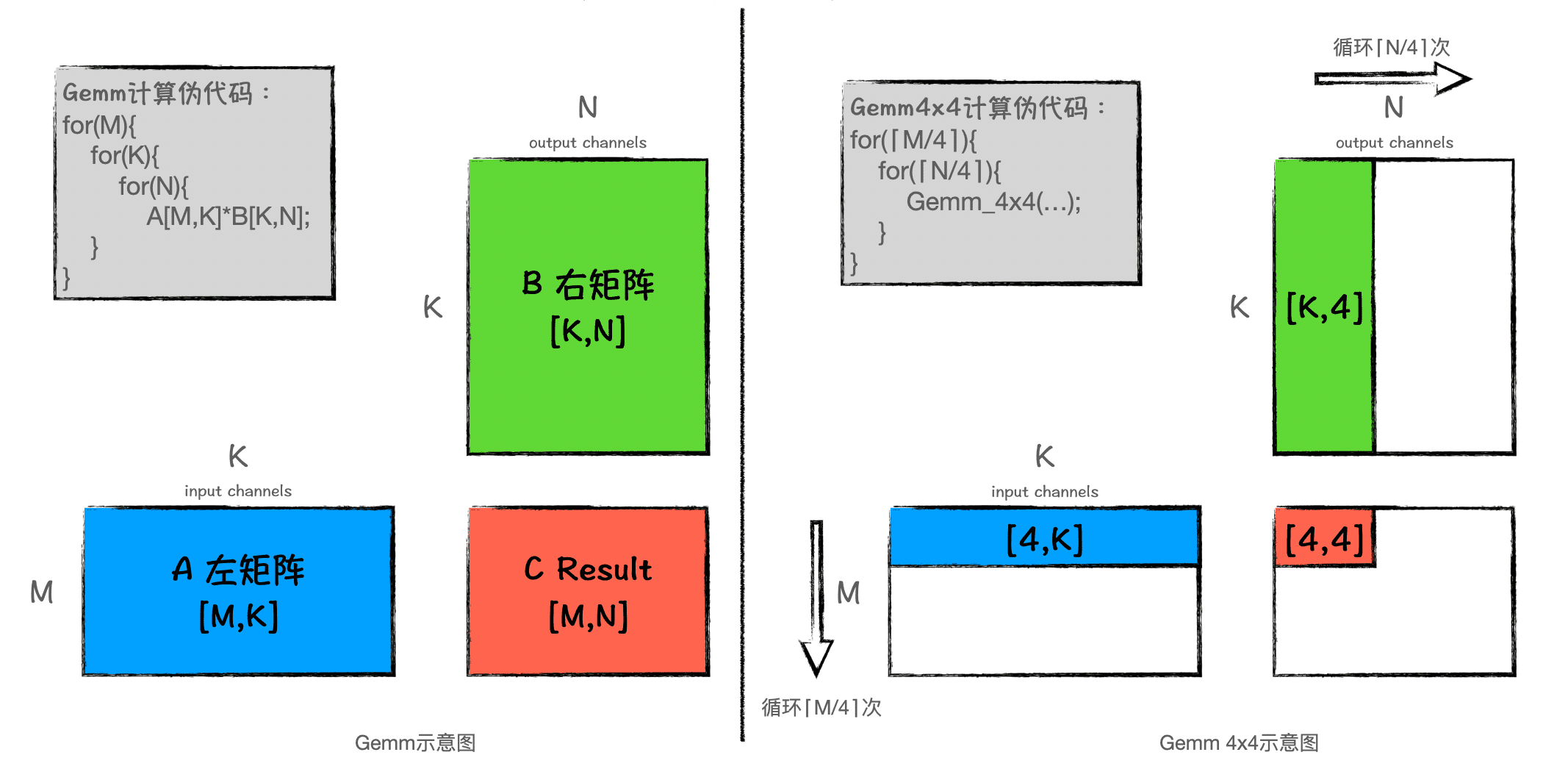
To avoid unnecessary cache swapping, blocking processing is performed. Discussing Why Blocking Matrix Optimization Works is a good read, I recommend learning from it.
After performing block operations in version 2, the
performance is still not satisfactory. This is because, although this
version superficially implements blocking logic, there are still some
small tricks in the calculation within the block that have not been
applied.
Version 3: Blocked Optimization Version
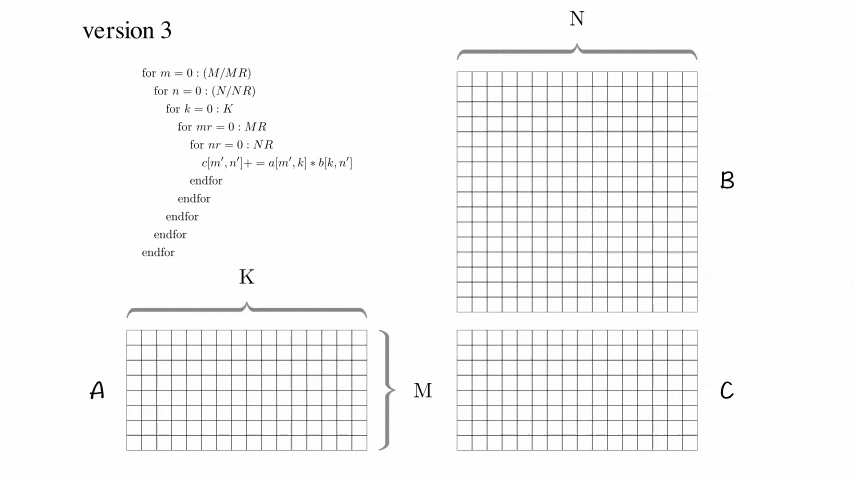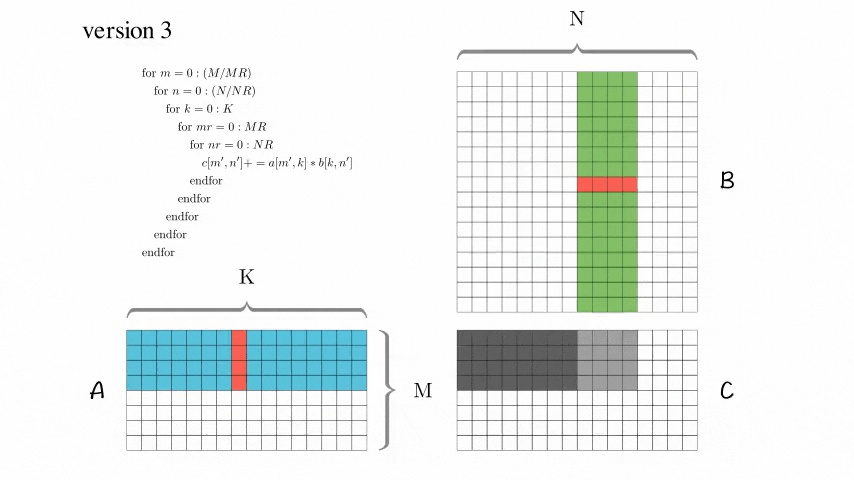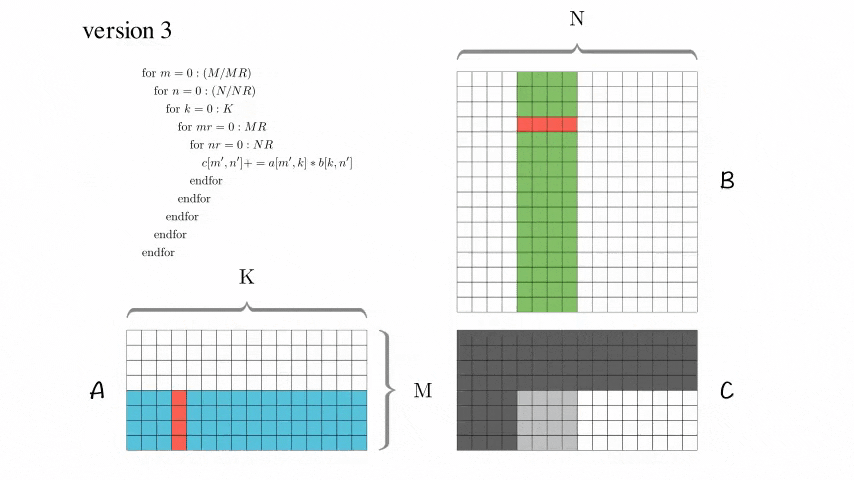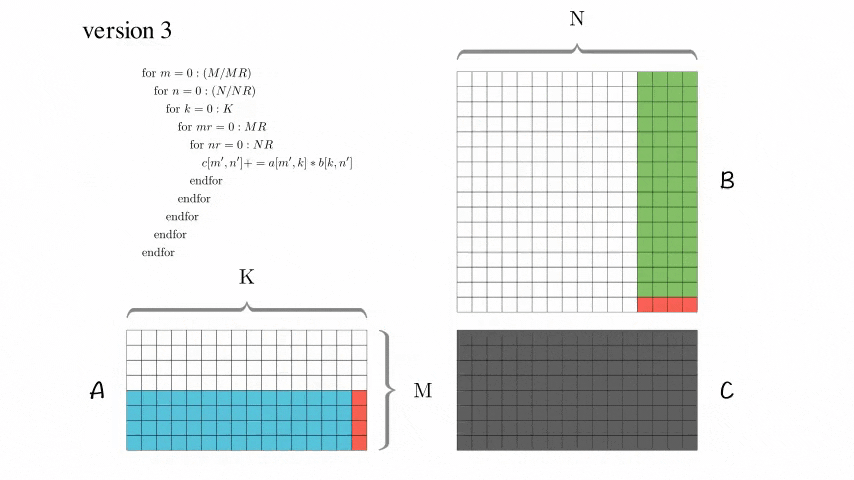
AddDot_4x4_opt has been added.
Several tricks are mentioned inBLISlab-tutorial:
- 2.4.2 Loop unrolling
- Updating loop index i and the pointer cp every time through the inner loop creates considerable overhead. For this reason, a compiler will perform loop unrolling.
- 2.4.3 Register variables
- Notice that computation can only happen if data is stored in registers. A compiler will automatically transform code so that the intermediate steps that place certain data in registers is inserted.
After using these tricks, this version has significantly improved performance!
However, for larger matrix sizes, the performance of this version is
still relatively low. Upon investigation, for example, after accessing
B[0,0], B[0,1], B[0,2], B[0,3], when accessing B[1,0], when the size is
large, there must be a cache miss. Therefore, it would be
great if the data could be rearranged in advance.
Version 4: B prepack Version
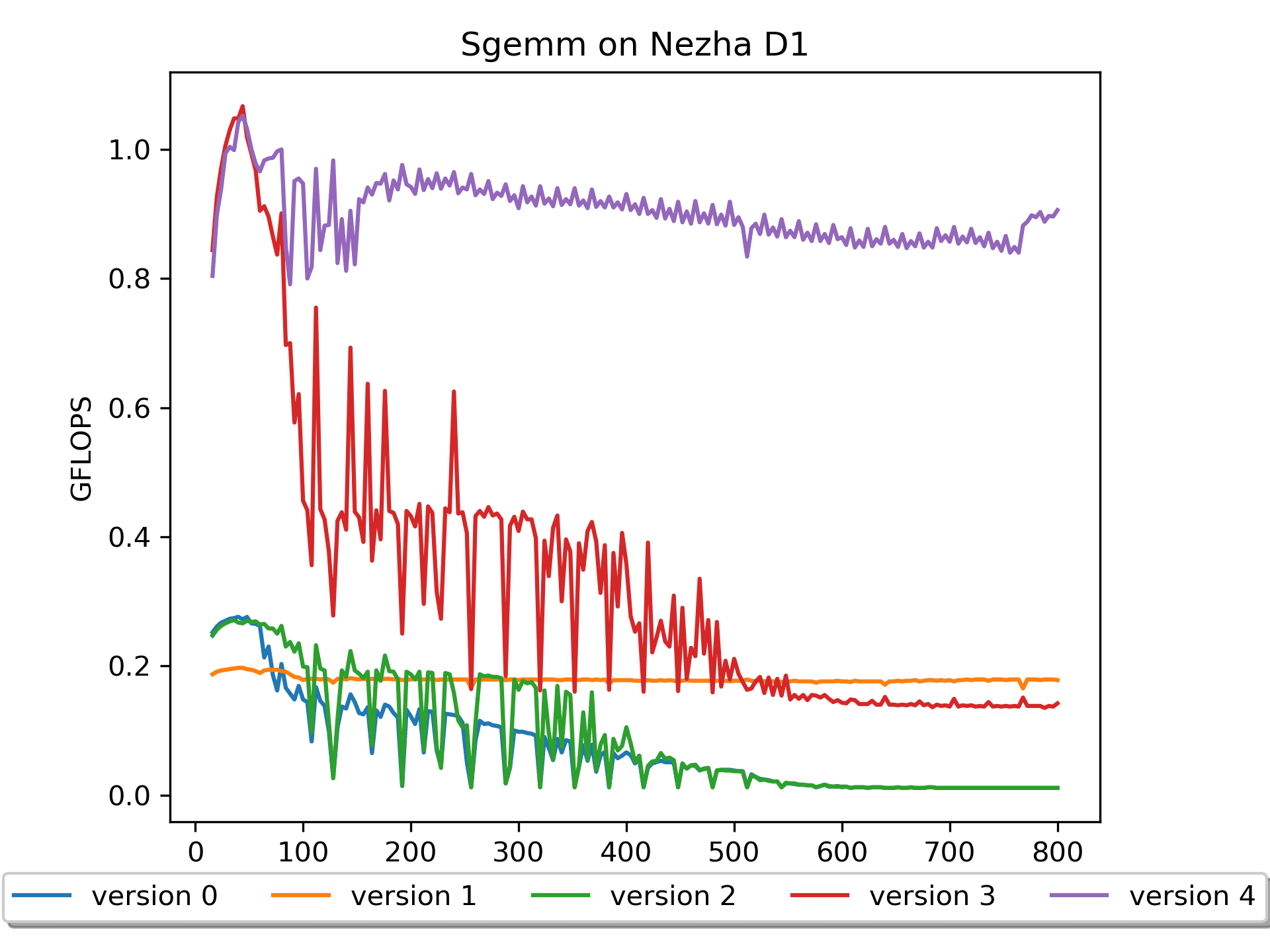

I assume matrix B is parameter, so we can perform
the pack operation in advance. Version 4
prepack matrix B, leading to further performance
improvement!
The reason for the performance improvement is evident: there is a
significant reduction in cache misses when accessing matrix
B. This is the first time I deeply realized the importance of
prepacking neural network weights before model
inference.
It can be seen that when the size is relatively large, the performance still declines. This should be due to a high number of cache misses when accessing matrix A. Should we pack A?
I assume matrix A is input, so packing A cannot be done in advance and must be included in the overall timing. Is it necessary?
Version 5: A pack & B prepack Version
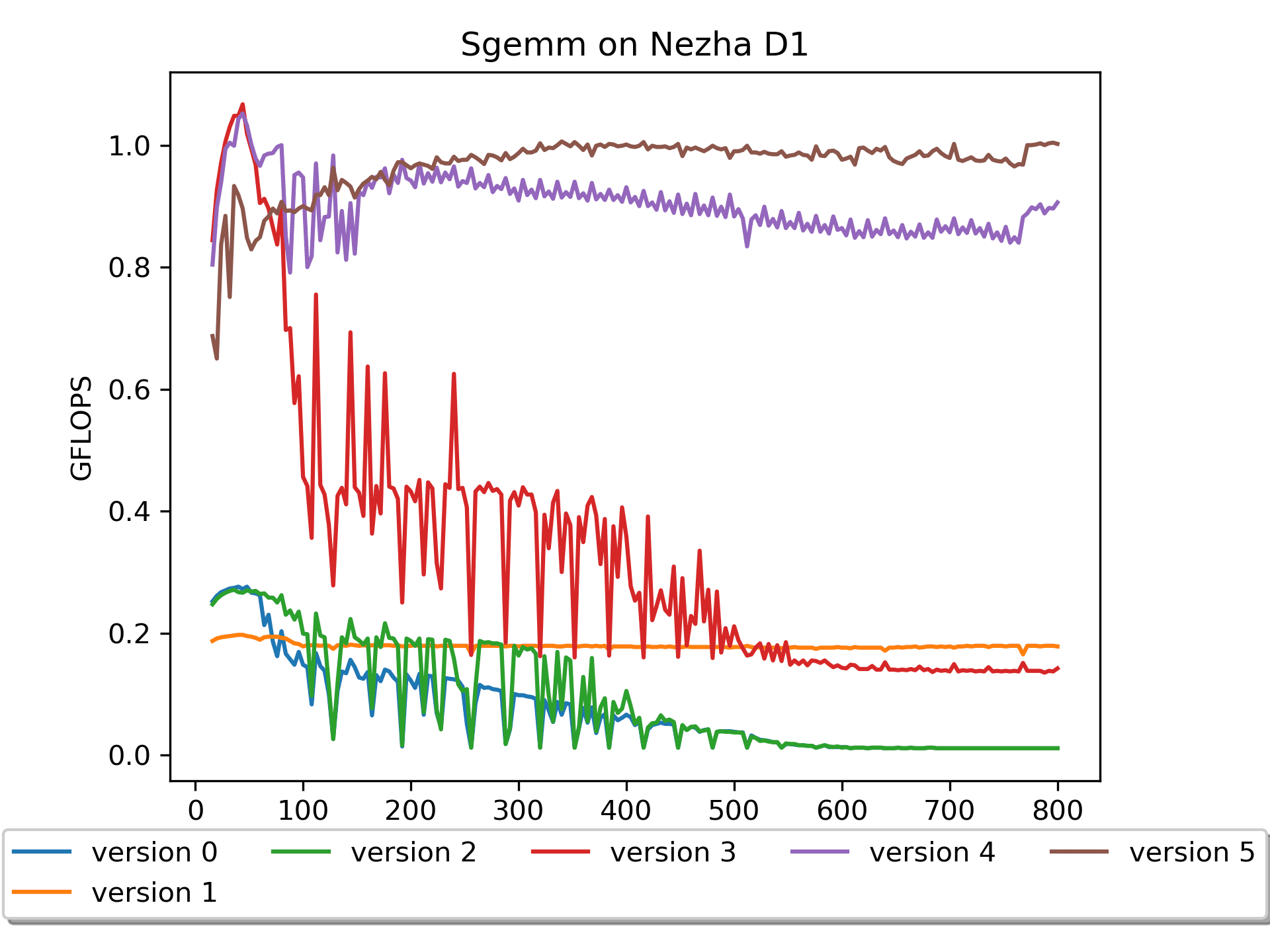
Based on Version 4, Version 5 performs packing on matrix A.
Here, since matrix A is assumed to be an input, packing A needs to be performed during computation, and this time consumption needs to be included in the timing.
The results are still pleasing, especially with large matrix sizes, achieving further performance improvements.
I initially approached this experiment with a trial-and-error mindset, considering the additional read of A and writing of packA. It seems the main challenge ahead lies in combating cache misses.
The current optimization direction has reached its limit. It's worth
trying to do some preload during the calculation
process.
Next, we'll move to assembly, work on vector calculations, and
implement preload in assembly.
Version 6: Assembly Version
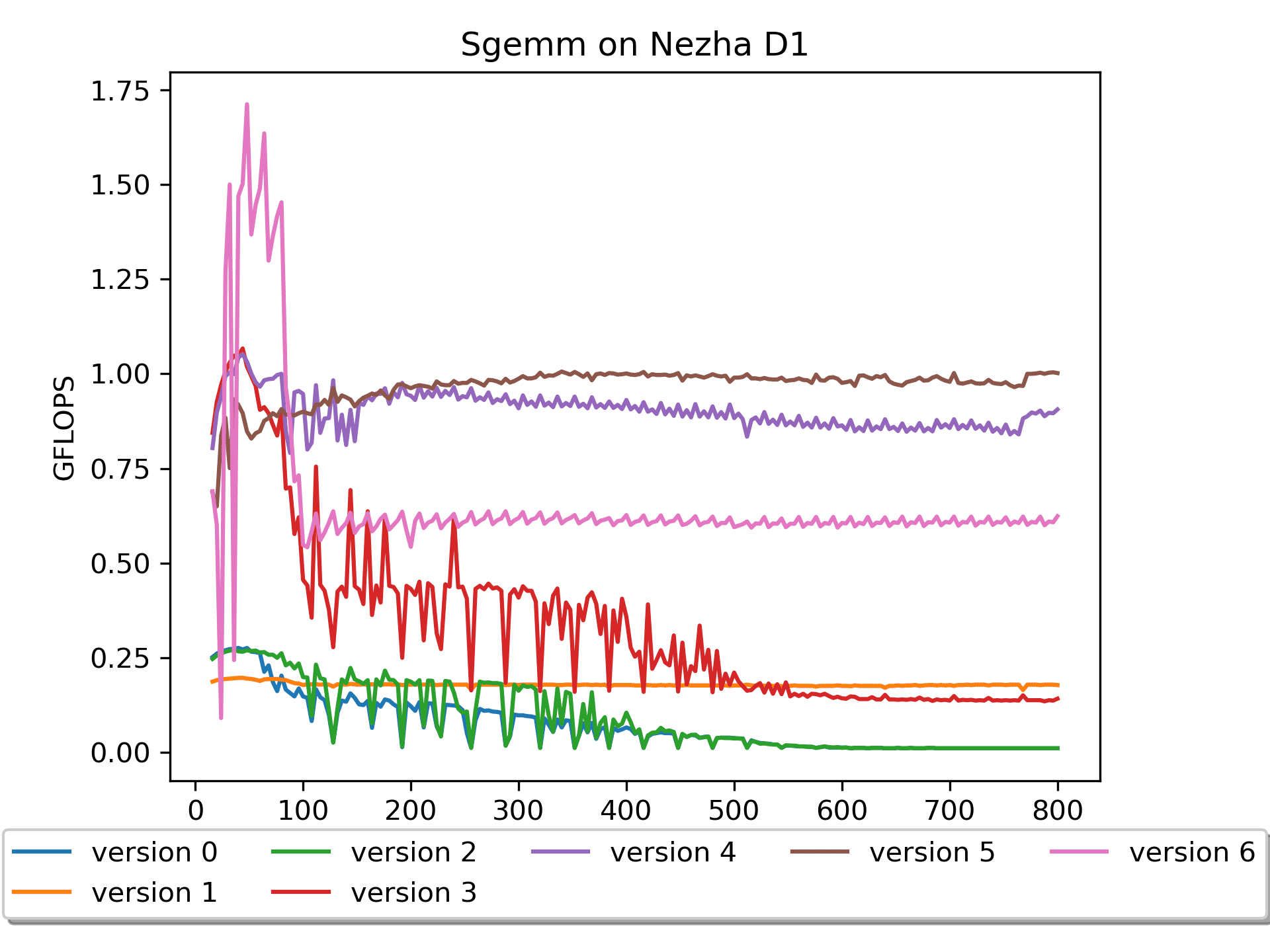
Brief explanation: A is not packed, but B is prepacked with 16 numbers.
1 | for ( i = 0; i < m; i += DGEMM_MR ) { // Start 2-nd loop |
Regarding the use of rvv instructions, I believe vsetvli
is essential, and vfmacc.vf is the mainstay.
I have learned a lot from OpenPPL Course | RISC-V Technical Analysis. They are truly professional! I recommend learning theoretical guidance and knowledge points from them, paying tribute to OpenPPL!
As for assembly operators, there are many details in assembly, and I strongly complain: writing assembly is really annoying! Especially the debugging process, it's torturous. The last time I wrote assembly was during my undergraduate classes. Picking it up again brings some novelty and excitement, and being able to control the execution of operators at a very fine granularity gives a great sense of accomplishment.
Regarding how the assembly files are implemented specifically, I believe the fastest way is to look at the assembly code. I won't explain it further here.
It should be noted that this version's performance is very poor. Why is that? It's another issue of loop order.
Version 7: Assembly Version with Loop Order Swapped
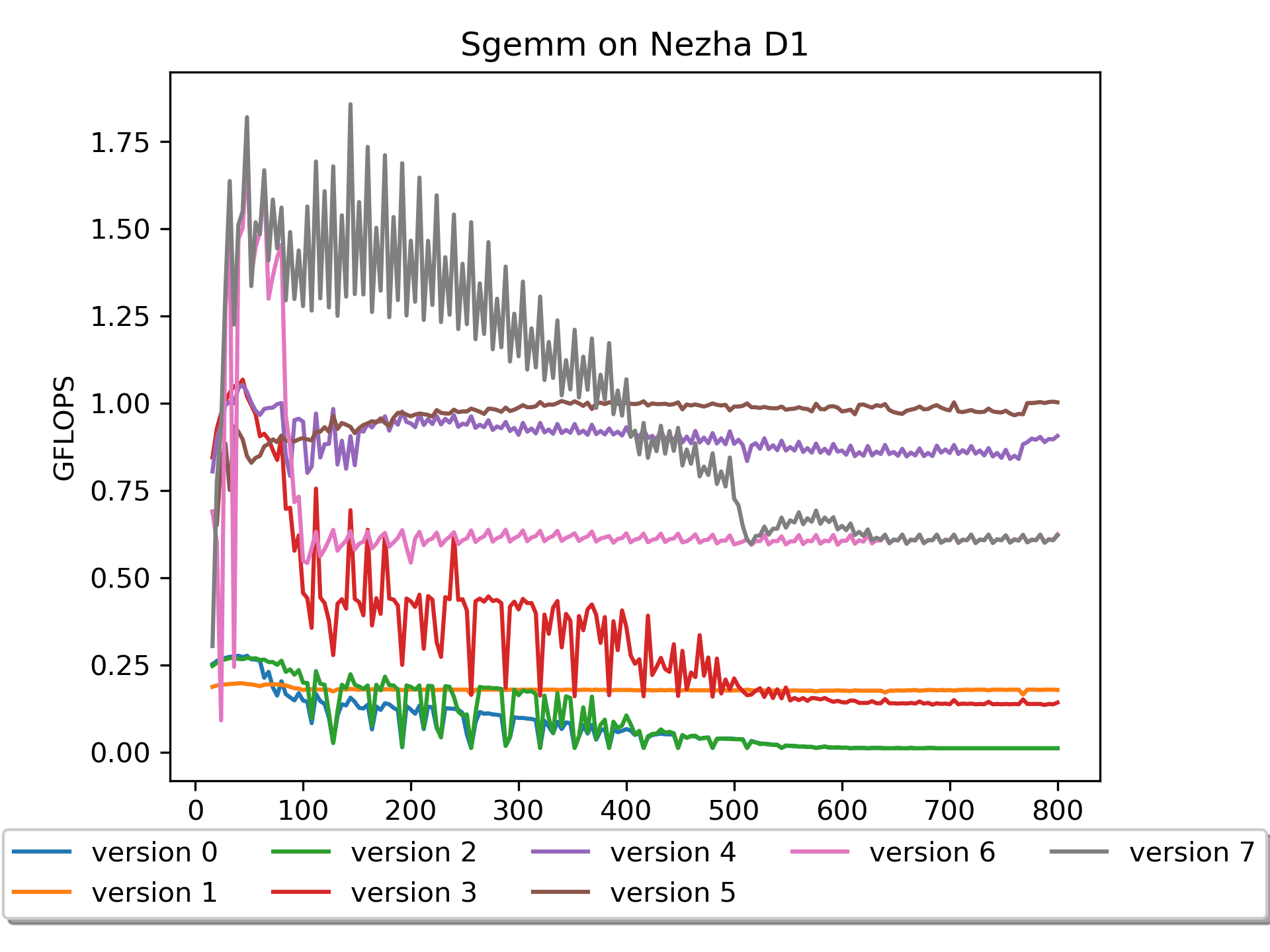
Brief explanation: A is not packed, but B is prepacked with 16 numbers.
1 | for ( j = 0; j < n; j += DGEMM_NR ) { // Start 2-st loop |
Reversing the order of loops, starting with the n-direction followed by the m-direction, significantly improves performance.
However, the performance of large-sized matrices is still not very
good. The root cause remains in memory access. The
computation of large-sized matrices in the roofline model
is considered compute-bound, where ideally the
compute time and memory access time should
overlap as much as possible. Currently, a significant amount of time is
spent on memory access (mostly due to cache miss!).
Version 8: Assembly Version with Preload
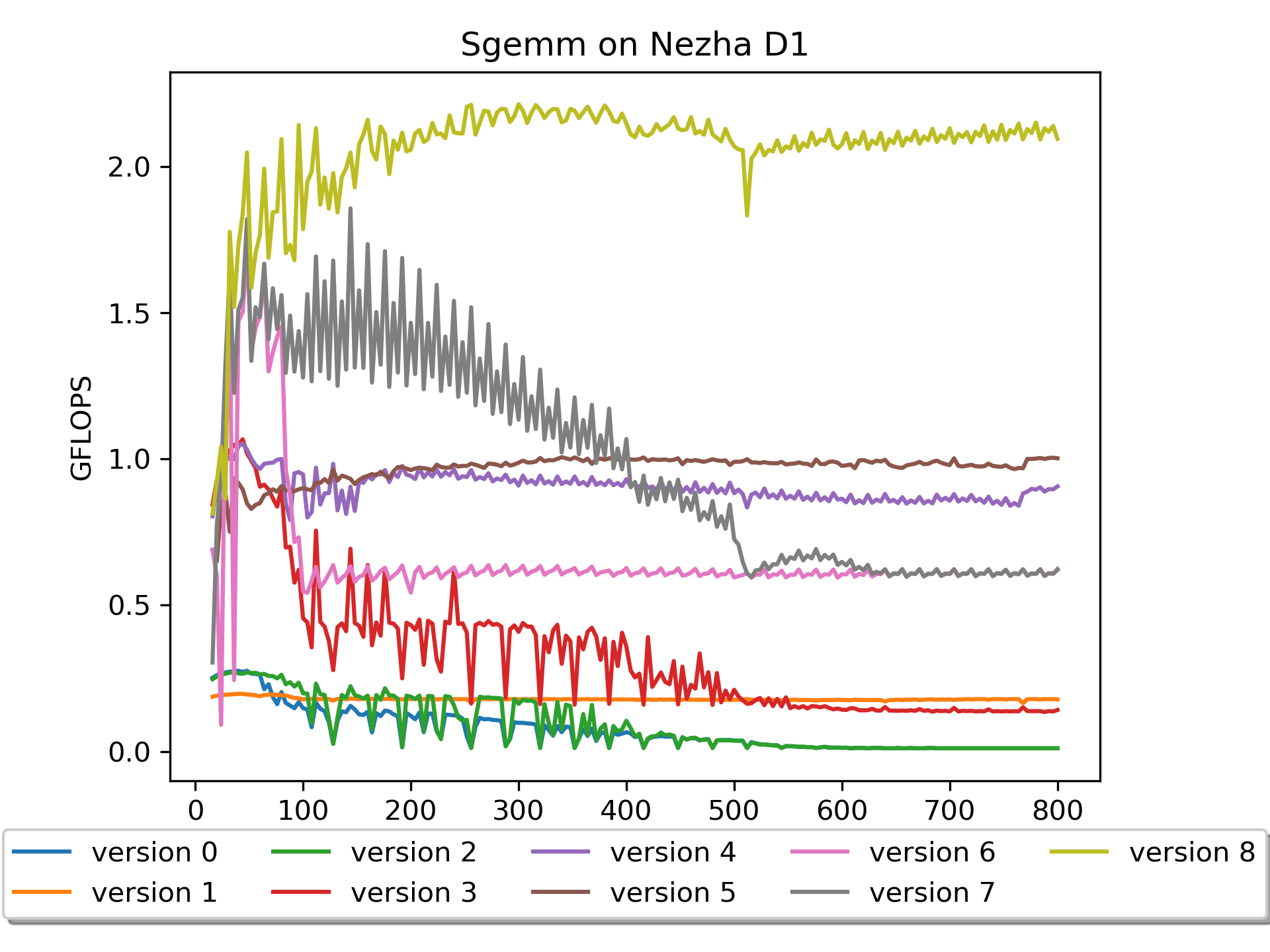
Brief Explanation: Matrix A is not packed, while Matrix
B undergoes prepackaging of 16 elements and includes a
preload operation.
The performance is explosive! It reaches a maximum of
2.212 GFLOPS.
Core operations:
1 | vfmacc.vf v16, ft0, v0 |
Inserting some load operations between
vfmacc.vf instructions preloads the data that will be used
later into the cache, significantly reducing
cache miss.
Initially, I was puzzled—how can the compute time and
memory access time overlap when the code seems to execute
sequentially? It wasn't until later that I understood the essence here,
which lies in the principle of cacheline. Indeed,
foundational knowledge is crucial!
Version 9: Assembly Version with A Packed
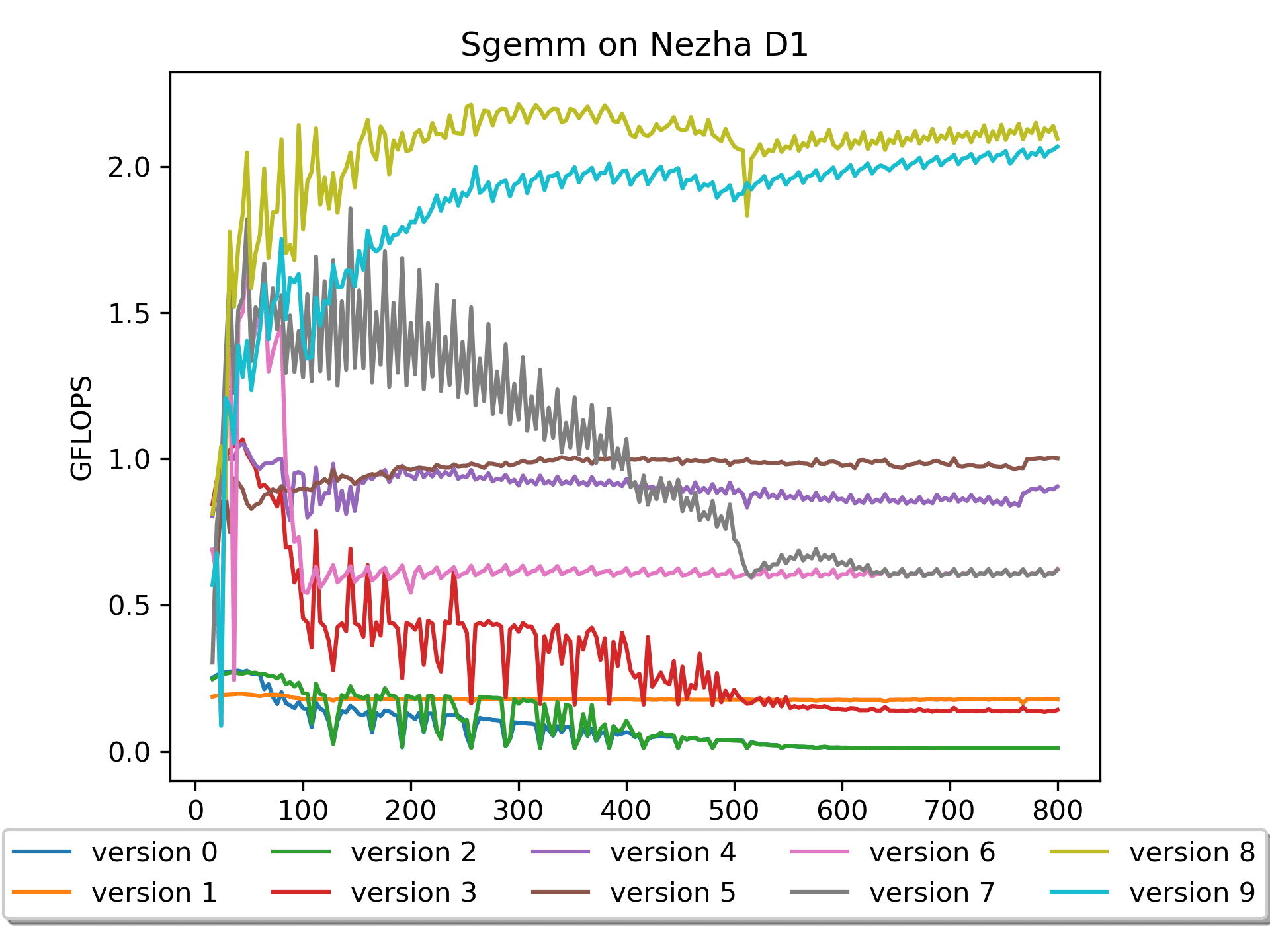
Based on previous experience, an attempt was made to
pack Matrix A, but surprisingly, the results were not very
good. A brief analysis suggests that the preload for Matrix A in this
version of the assembly code might not be optimized.
In the previous version, although A wasn't packed, there was preload for A's 4 rows, which also addressed the pain point of cache miss for Matrix A.
Conclusion
To continue optimizing this operator, there is still much to be done, such as rearranging pipelines in assembly.
As mentioned in the OpenPPL Course | RISC-V Technical Analysis, using
vf instructions can achieve 80% of the theoretical peak,
which is 4*80%, 3.2 GFLOPs. I currently have only
2.121 GFLOPs, indicating there's still a lot of room for
optimization theoretically.
Furthermore, the RVV currently uses version 0.7.1, and it seems
there's still much work to be done in RVV instruction optimization, such
as the serious efficiency problem encountered with vlw.
In conclusion, working on these tasks has allowed me to learn a lot from many experts, and I'm very grateful. I also hope this article can help more people.
Acknowledgement
BLISlab: A Sandbox for Optimizing GEMM
This project introduced me to how to optimize GEMM
-
I conduct experiments and exploration based on this project
Thanks to Mr. Ding for your guidance.
References
Anatomy of High-Performance Matrix Multiplication


