最近做了一些转置卷积的相关部署工作,最开始搞的时候其实有点晕头转向的,总是试图在用卷积的计算方式反过来理解转置卷积,尤其是看到padding部分和stride部分,搞得我头更大了,心想怎么这么反人类?(后来发现是我理解的问题,其实一点也不反人类)
现在也算是了解了具体工作机制以及加速方式,在这里整理总结一下。欢迎留言、指正 :)
转置卷积是什么?
定义
转置卷积有时候也被称为反卷积,我个人认为反卷积有很强的误导性,因为这并不是卷积的逆运算,还是叫转置卷积比较好。
转置卷积在深度学习中表示为卷积的一个逆向过程,可以根据卷积核大小和输出的大小,恢复卷积前的feature map尺寸,而不是恢复原始值。
如果将卷积表示为y=Cx,转置卷积则是将的输入输出互换:x = CTy
其中, CT表示矩阵转置。
详细定义这里就不仔细介绍了,上文里的各个参考文档里说的都很明白。
需要注意
总结一下我认为的最重要的(最开始纠结了很久的)几个点:
转置卷积不是恢复原始值,而是恢复原始尺寸(所以不要试图从卷积的逆运算角度考虑)
padding方式和卷积的padding是不一样的,转置卷积的实际padding是k-p-1stride在这里用途不是跳几个数,而是用于判断填充几个0用公式法直接计算的话,首先对卷积核做中心对称操作(矩阵旋转180°)
不考虑性能的话,直接按照转置卷积定义写。反之,一定要优化,不然慢得很。
The table below summarizes the two convolutions, standard and transposed.
| Conv Type | Operation | Zero Insertions | Padding | Stride | Output Size |
|---|---|---|---|---|---|
| Standard | Downsampling | 0 | p | s | (i+2p-k)/s+1 |
| Transposed | Upsampling | (s-1) | (k-p-1) | 1 | (i-1)*s+k-2p |
注意注意,有没有觉得转置卷积的
padding和stride很反人类?这和我理解的完全不一样啊?其实不然,这里的padding和stride指的其实是转置卷积结果的padding和stride。即,逆向来看的情况下,卷积的padding和stride。
为了说明转置卷积如何
推理计算,本文第二章节会使用表格所示的参数计算方式,直到第三章节才会从卷积的角度来看,到时候你会恍然大悟,padding和stride的含义,原来如此。
转置卷积的计算
从最简单的开始
conv_transpose有一种最直接的计算方式:首先对卷积核做中心对称操作(矩阵旋转180°),并对输入feature map进行插0,然后把旋转后的卷积核和插0后的feature map进行卷积操作
现在假设输入的feature map是3x3大小,kernel size是3x3大小,stride为1,
padding为0,即:
input_sz: 3
kernel_sz = 3
stride = 1
padding_sz = 0写一段torch代码计算一下: 1
2
3
4
5import torch
X = torch.Tensor([[[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]])
K = torch.Tensor([[[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]])
Y = torch.nn.functional.conv_transpose2d(X, K, stride=1, padding=0)
print(Y)
得到输出结果: 1
2
3
4
5tensor([[[[ 1., 4., 10., 12., 9.],
[ 8., 26., 56., 54., 36.],
[ 30., 84., 165., 144., 90.],
[ 56., 134., 236., 186., 108.],
[ 49., 112., 190., 144., 81.]]]])
- 对输入
X进行处理,插入(s-1)的0,做(k-p-1)的padding
在这个例子中,s=1,则无需插入0,只进行(k-p-1)=(3-0-1)=2的padding。输入X则转化为
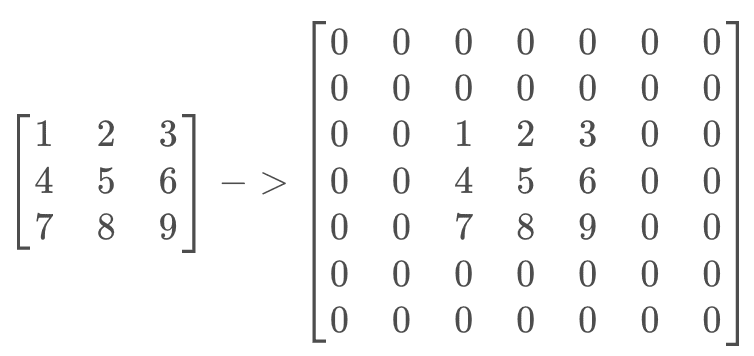
- 对卷积核
K进行中心对称操作
卷积核K则转化为
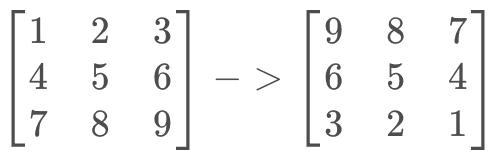
- 进行卷积计算
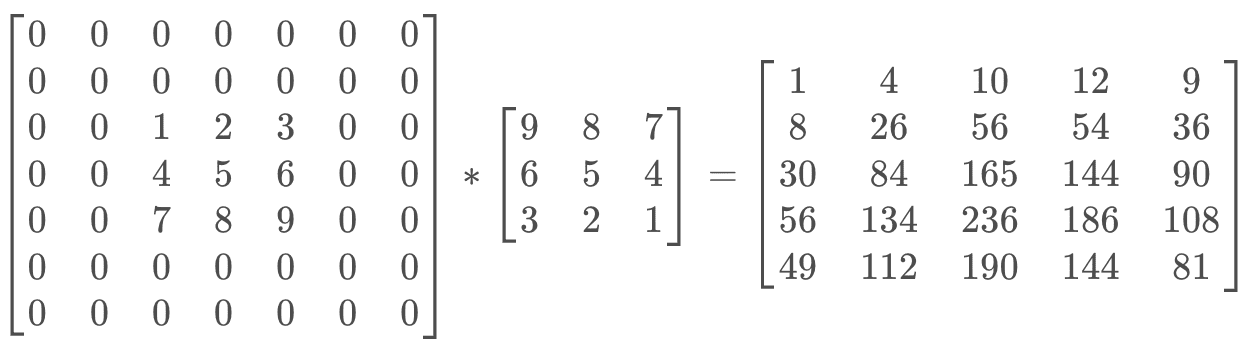
- gif图解
![]()
考虑stride
我个人建议不要用卷积的stride来理解转置卷积的stride,stride在这里用途不是跳几个数,而是用于判断填充几个0。
现在假设输入的feature map是3x3大小,kernel size是3x3大小,stride为2,
padding为0,即:
input_sz: 3
kernel_sz = 3
stride = 2
padding_sz = 0同样,写一段torch代码计算一下: 1
2
3
4
5import torch
X = torch.Tensor([[[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]])
K = torch.Tensor([[[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]])
Y = torch.nn.functional.conv_transpose2d(X, K, stride=2, padding=0)
print(Y)
得到输出结果: 1
2
3
4
5
6
7tensor([[[[ 1., 2., 5., 4., 9., 6., 9.],
[ 4., 5., 14., 10., 24., 15., 18.],
[ 11., 16., 40., 26., 60., 36., 45.],
[ 16., 20., 44., 25., 54., 30., 36.],
[ 35., 46., 100., 56., 120., 66., 81.],
[ 28., 35., 74., 40., 84., 45., 54.],
[ 49., 56., 119., 64., 135., 72., 81.]]]])
- 对输入
X进行处理,插入(s-1)的0,做(k-p-1)的padding
在这个例子中,s=2,需插入1个0,进行(k-p-1)=(3-0-1)=2的padding。输入X则转化为
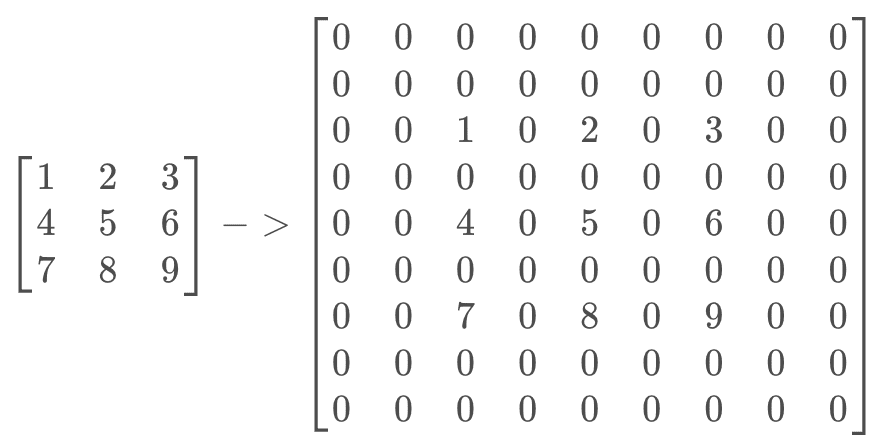
- 对卷积核K进行中心对称操作
卷积核K则转化为
- 进行卷积计算
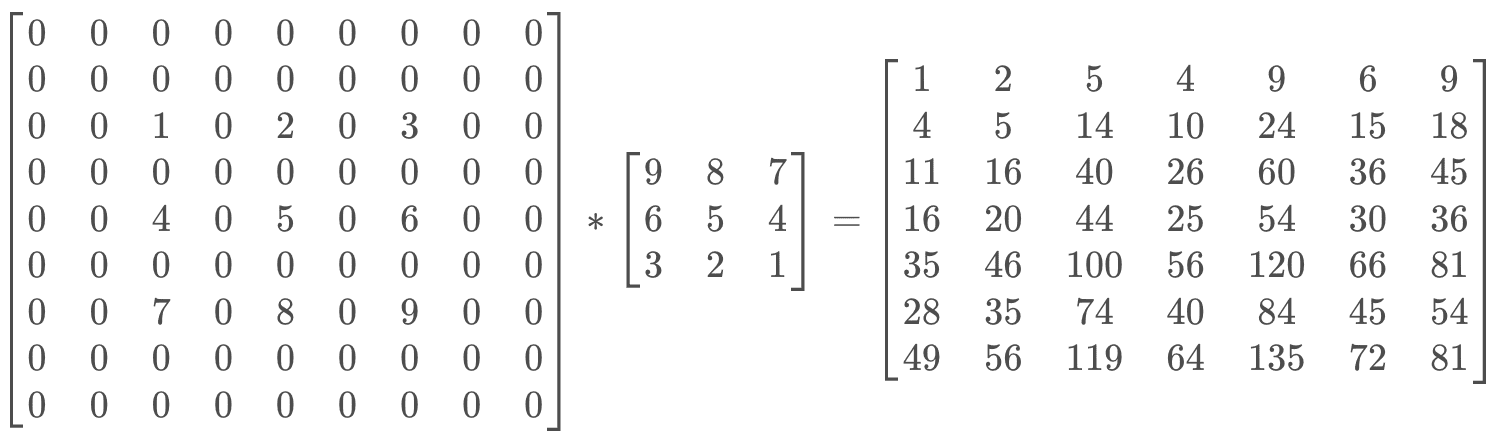
- gif图解
![]()
考虑padding
我最开始在padding这里疑惑了好一会儿,老是在从卷积的角度想转置卷积的padding。就很疑惑,怎么padding越大,计算结果的feature map越小呢?
后来暂时不想具体物理含义了,直接认为转置卷积的实际padding是k-p-1,万事大吉。(第三章节会解padding这个参数)
实际上,tensorflow的padding计算还是有点差异的,除了上面所说的计算,在计算padding的时候还有一个专门针对转置卷积的
offset,这可能会导致 左右/上下 的padding数不一致。 为什么这么做呢?个人认为要从转置卷积的目的来看————还原原始feature map的尺寸。 本文暂不考虑这种情况,感兴趣的可以查看tensorflow源码。
现在假设输入的feature map是3x3大小,kernel size是3x3大小,stride为1,
padding为1,即:
input_sz: 3
kernel_sz = 3
stride = 1
padding_sz = 1写一段torch代码计算一下: 1
2
3
4
5import torch
X = torch.Tensor([[[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]])
K = torch.Tensor([[[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]])
Y = torch.nn.functional.conv_transpose2d(X, K, stride=1, padding=1)
print(Y)
得到输出结果: 1
2
3tensor([[[[ 26., 56., 54.],
[ 84., 165., 144.],
[134., 236., 186.]]]])
- 对输入
X进行处理,插入(s-1)的0,做(k-p-1)的padding
在这个例子中,s=1,则无需插入0,只进行(k-p-1)=(3-1-1)=1的padding。输入X则转化为
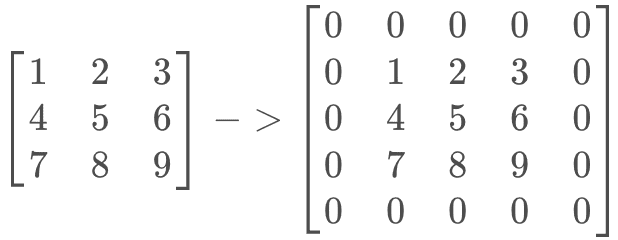
- 对卷积核
K进行中心对称操作
卷积核K则转化为
- 进行卷积计算
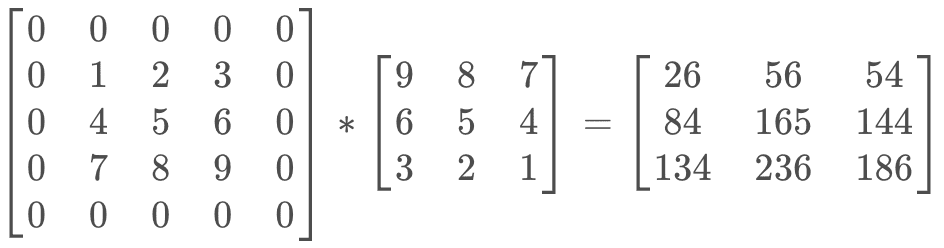
- gif图解
![]()
考虑dilation
这里就不考虑了,和卷积一样的,很容易理解。
转置卷积的理解
初次见到转置卷积的时候,我看到conv_arithmetic和What is Transposed Convolutional Layer里面的动图计算是很开心的,毕竟这有助于我理解转置卷积是如何计算的。
但后来发现,了解计算过程看这些动图是比较好的,但是要是理解转置卷积,这些动图很容易误导。于是我写代码生成了一些动图,虽然有点丑,但是padding部分和stride部分立刻搞得清清楚楚明明白白了。
stride=1,padding=0
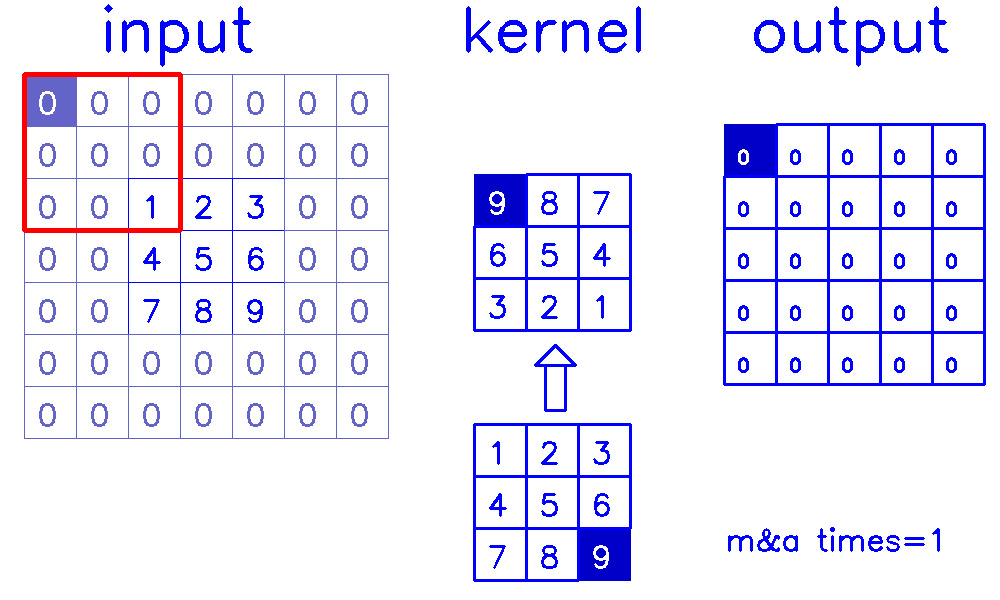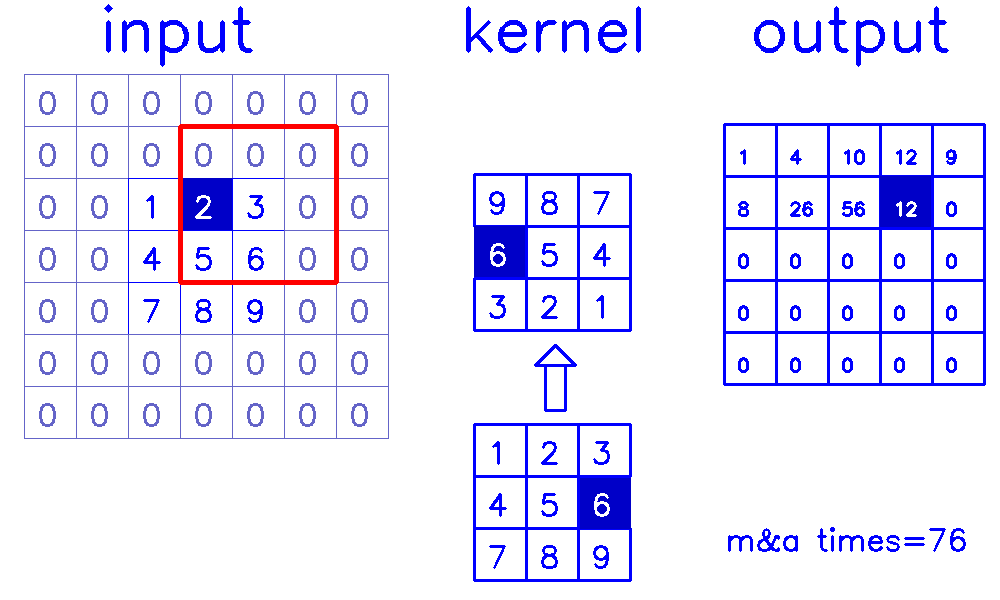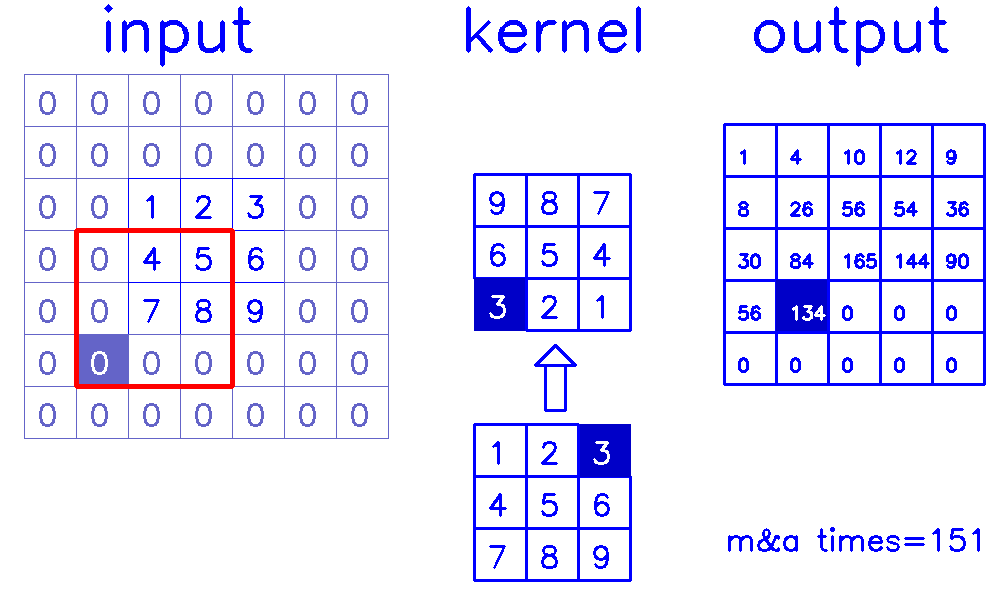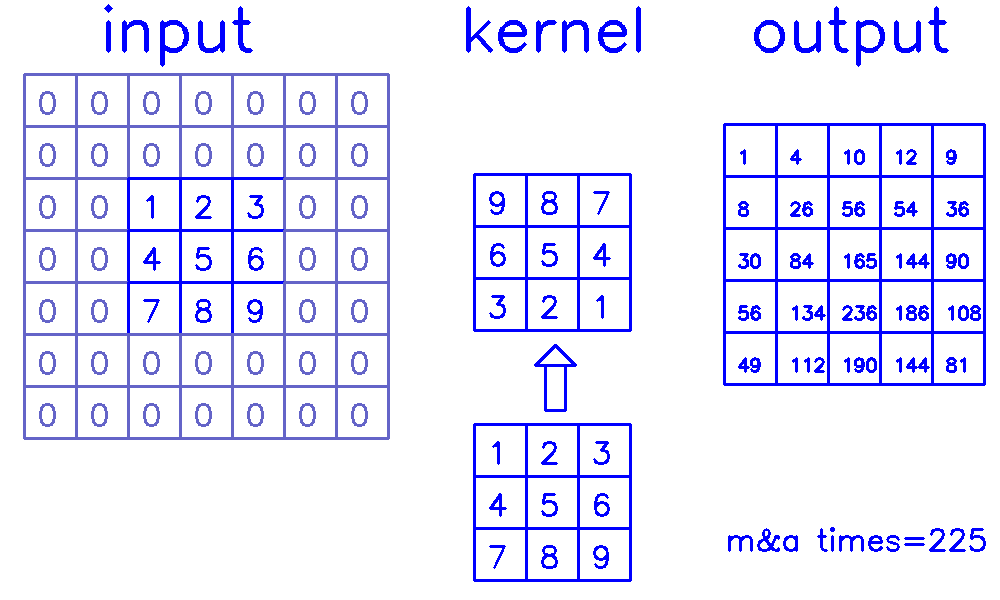
- 从input的角度来看,插入
(s-1)的0,做(k-p-1)的padding。在这个例子中,s=1,则无需插入0,只进行(k-p-1)=(3-0-1)=2的padding。
我们来换个角度看整个计算过程:
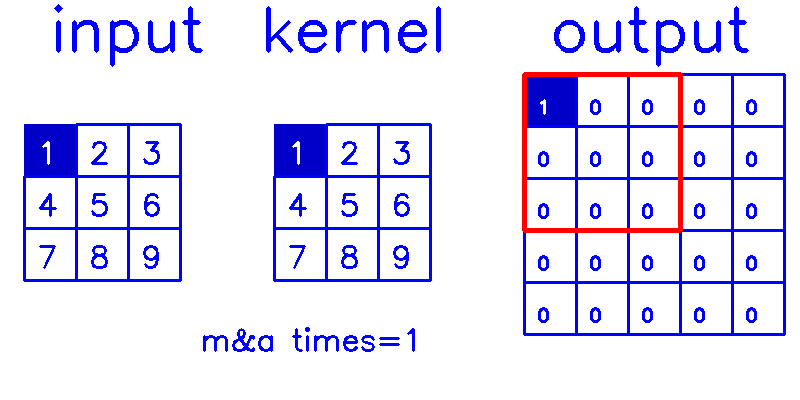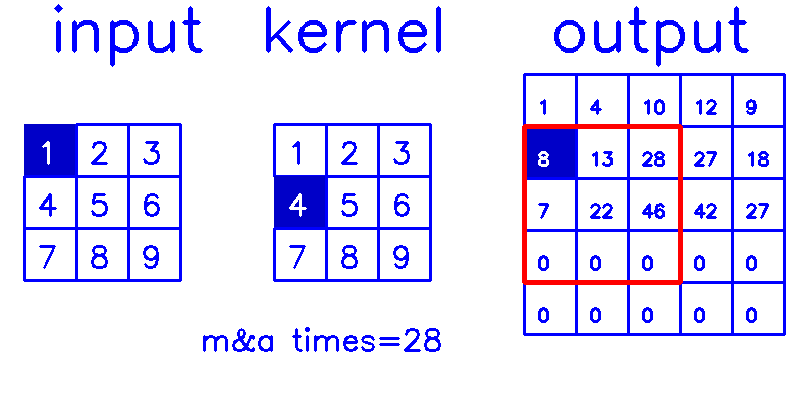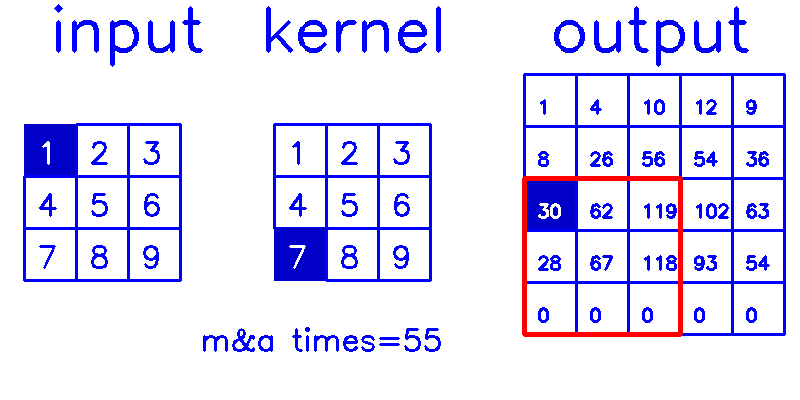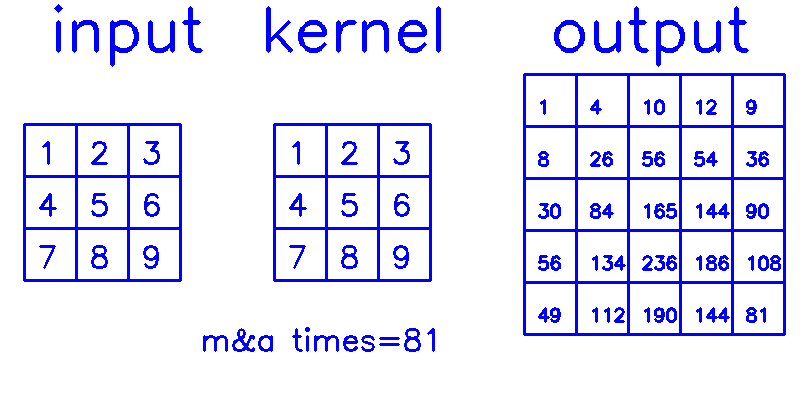
- 从output的角度来看,stride=1,padding=0(你get到这个点了吗?!)
stride=1,padding=1
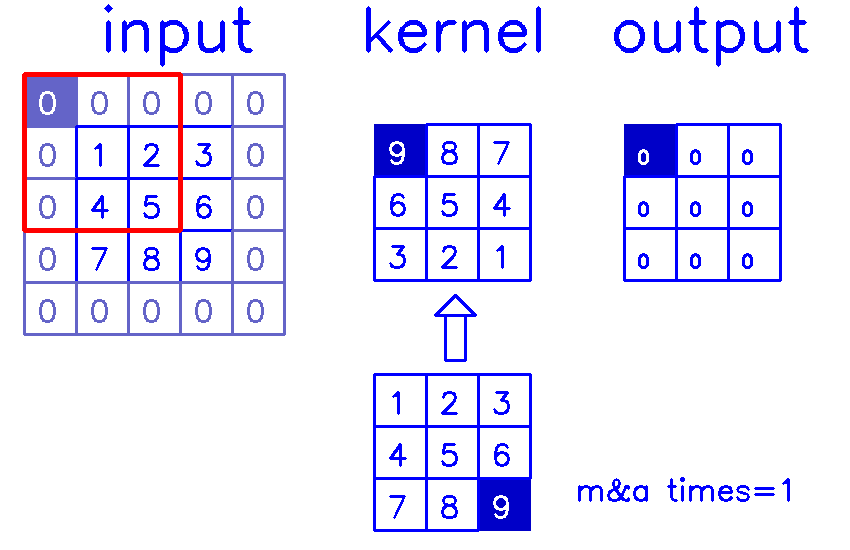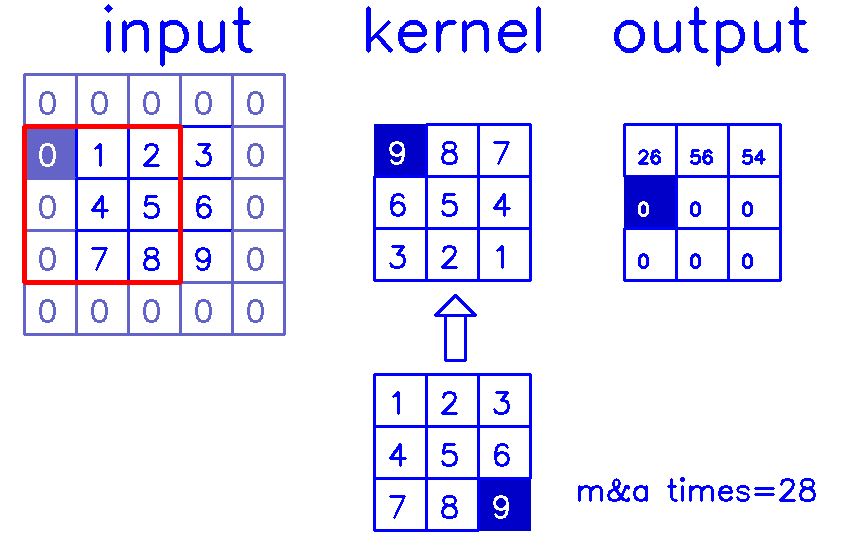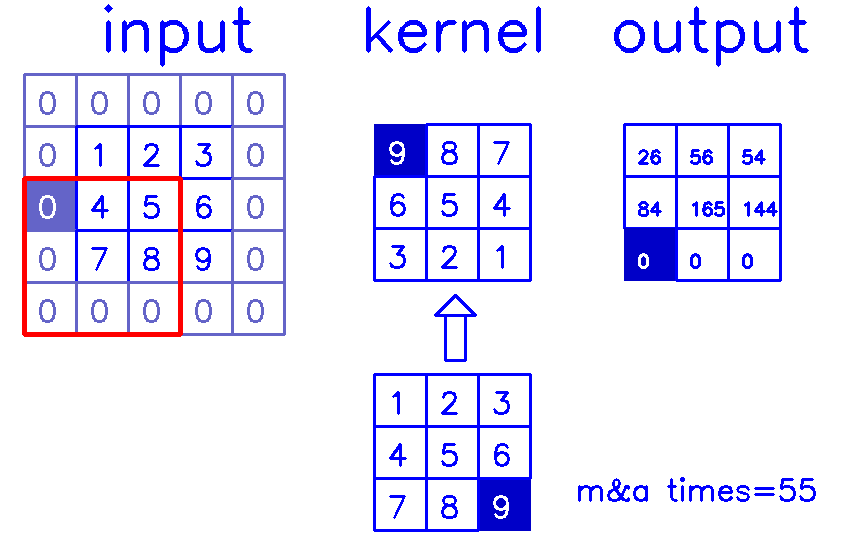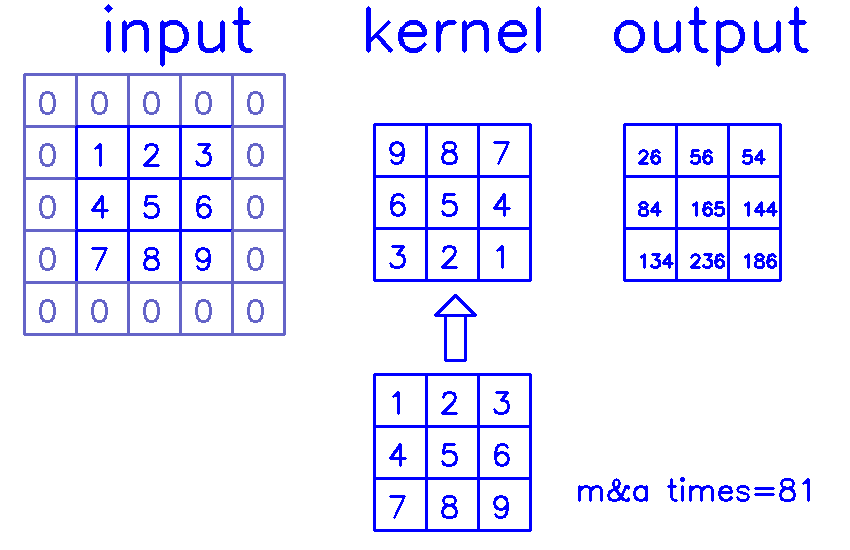
- 从input的角度来看,插入
(s-1)的0,做(k-p-1)的padding。在这个例子中,s=1,则无需插入0,只进行(k-p-1)=(3-1-1)=1的padding。
同样,我们来换个角度看整个计算过程:
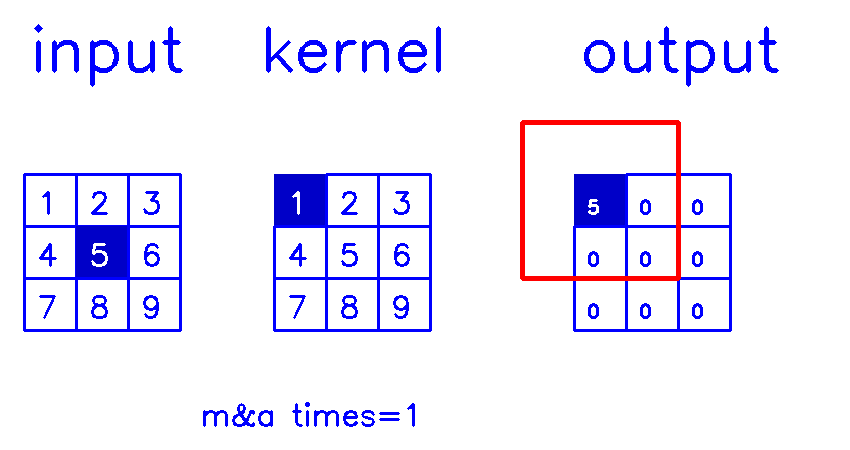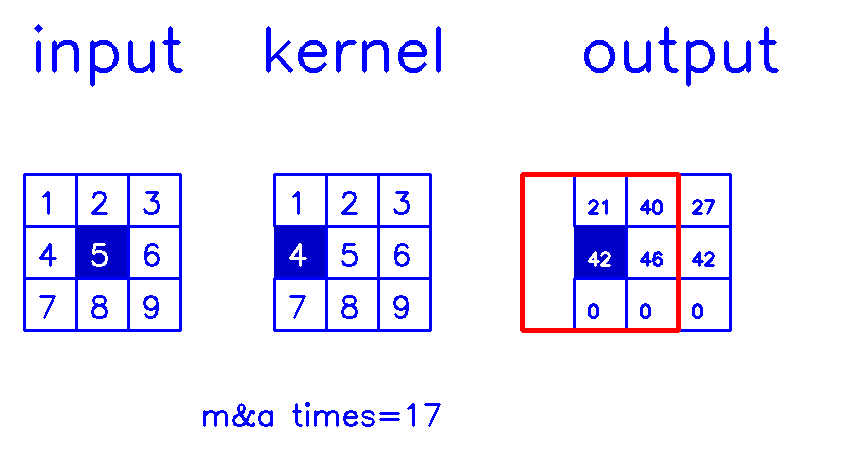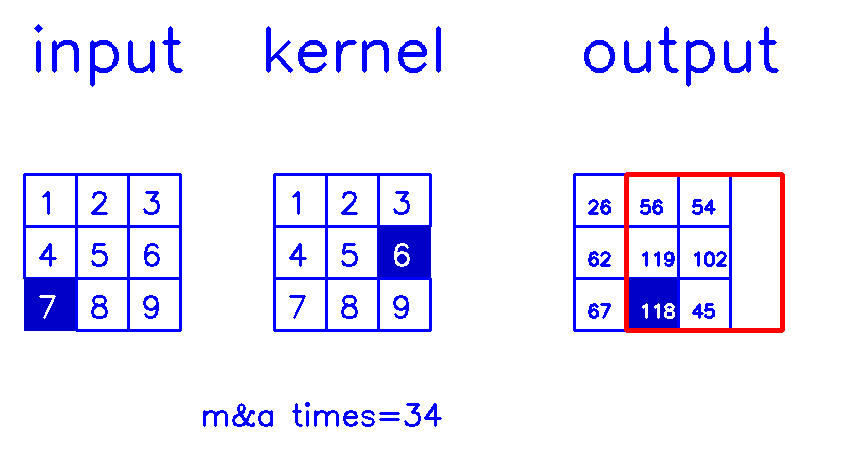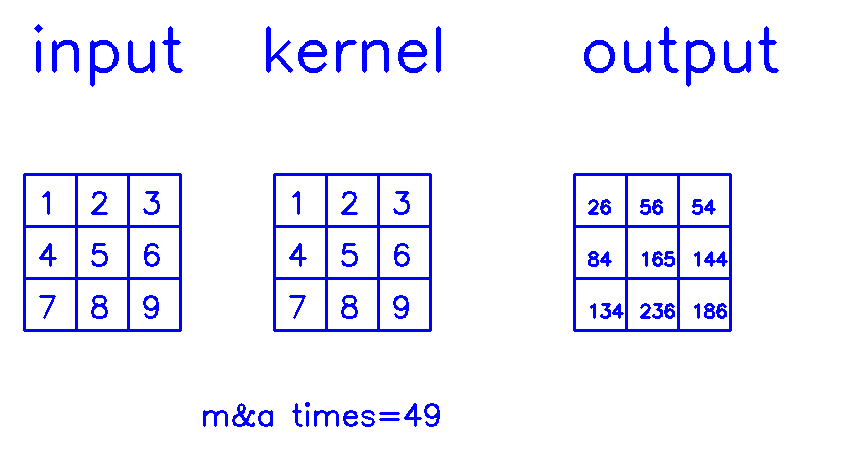
- 从output的角度来看,stride=1,padding=1
相信你已经明白,我在最开始说的,padding和stride指的其实是转置卷积结果的padding和stride这句话了吧?
stride=2,padding=0
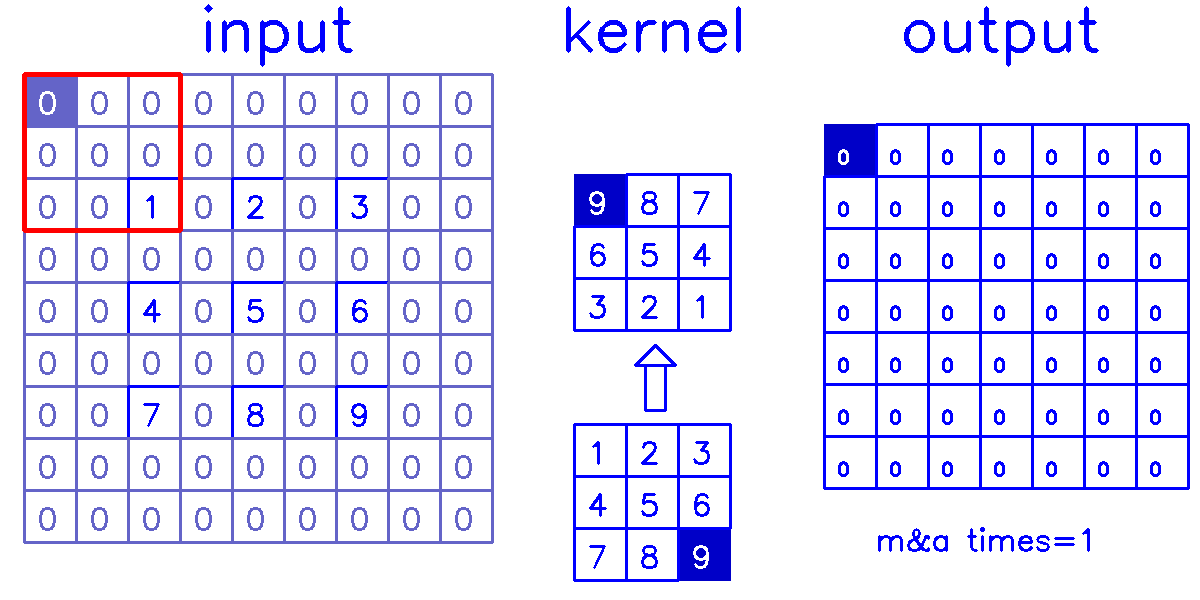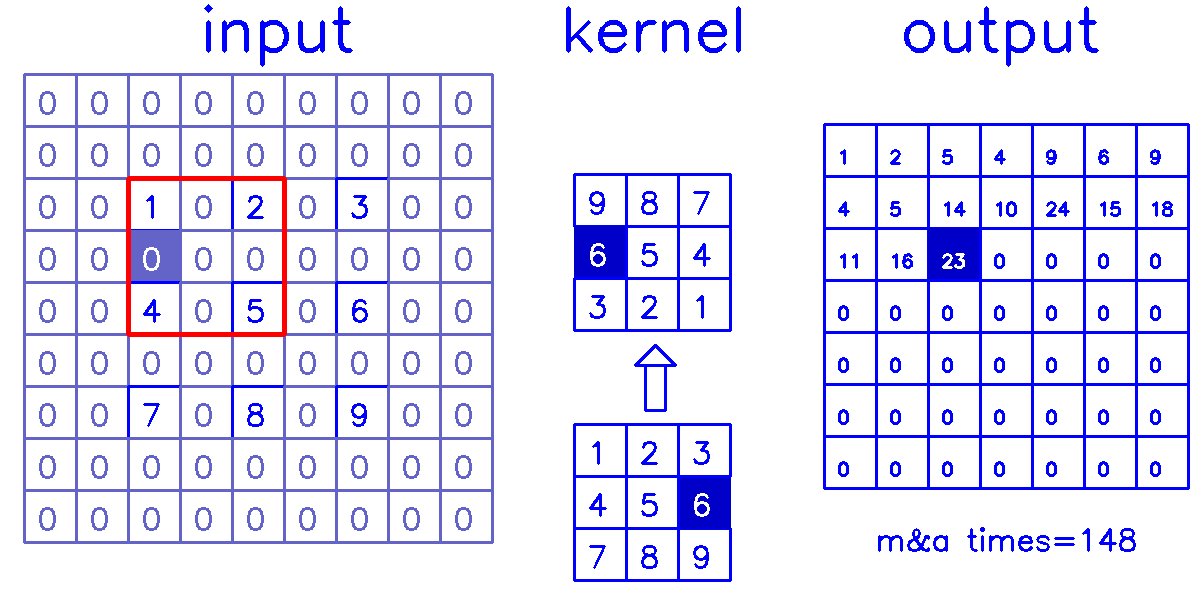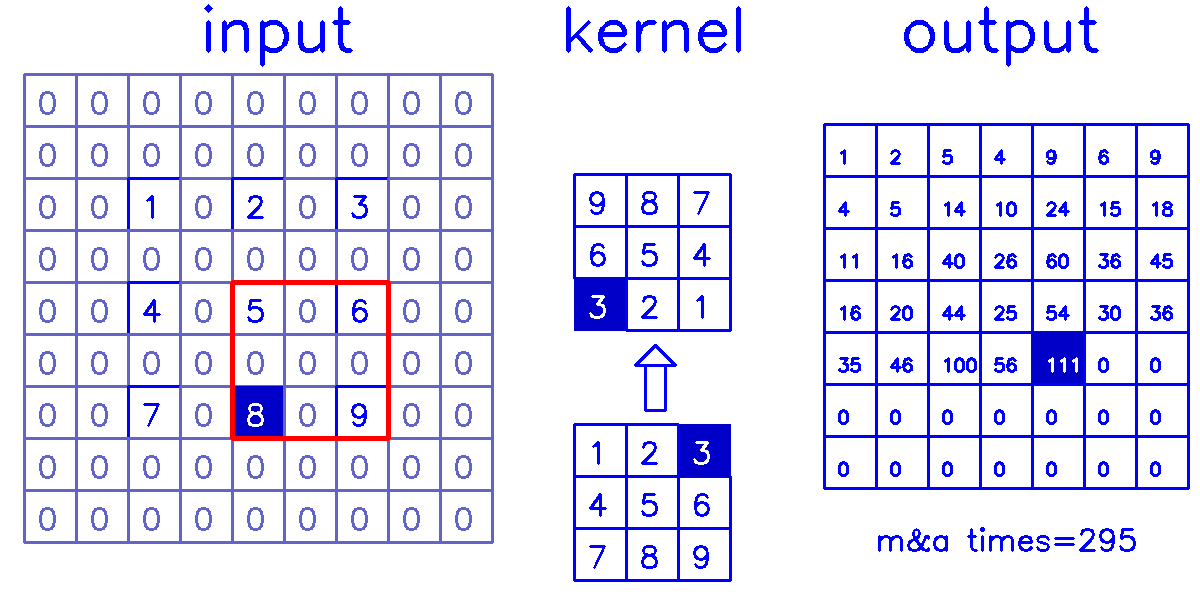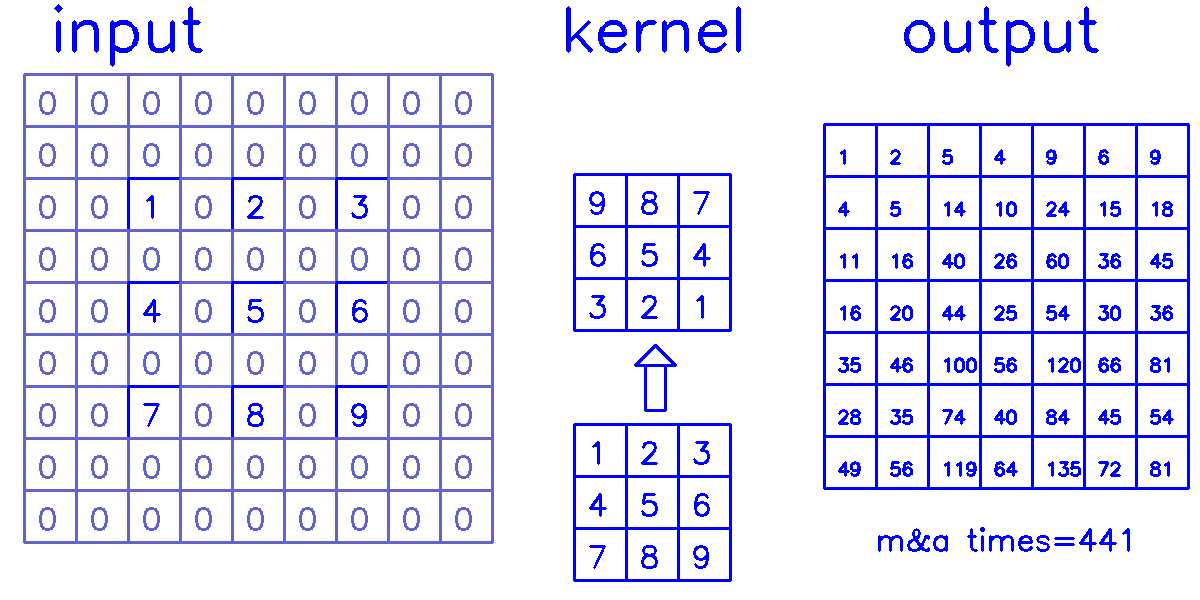
- 从input的角度来看,插入
(s-1)的0,做(k-p-1)的padding。在这个例子中,s=2,需插入1个0,然后进行(k-p-1)=(3-0-1)=2的padding。
我们来换个角度看整个计算过程:
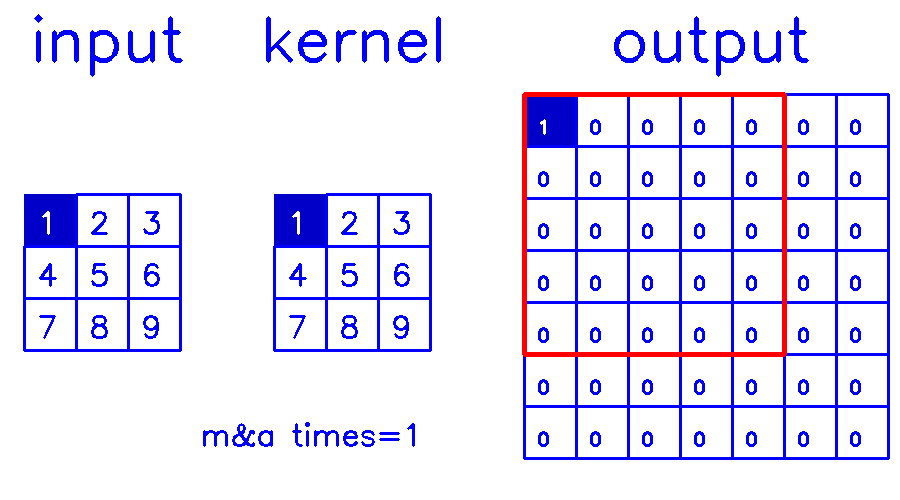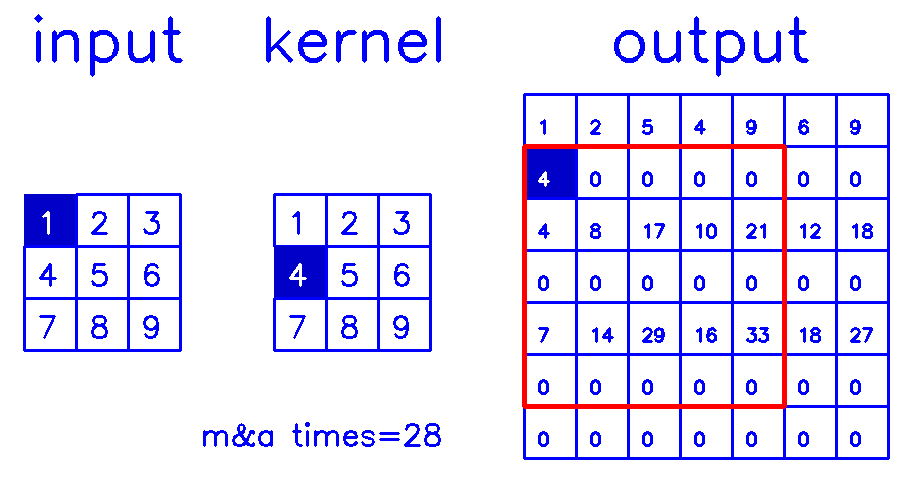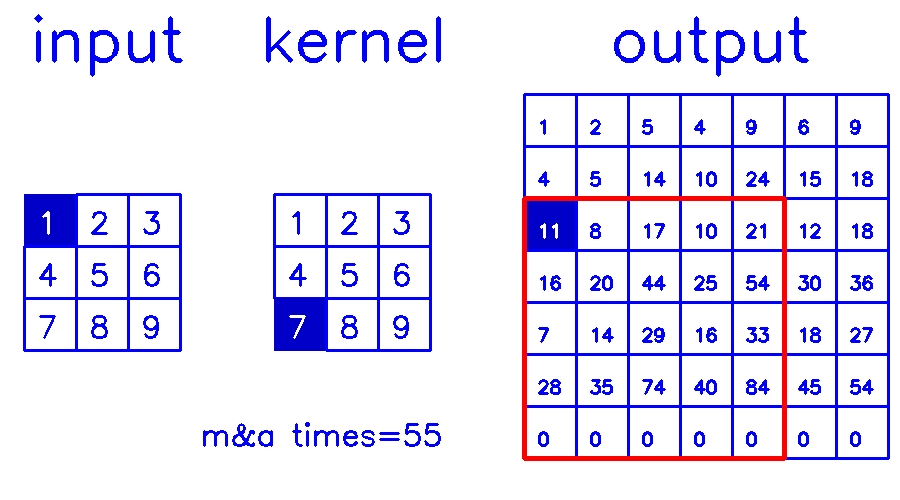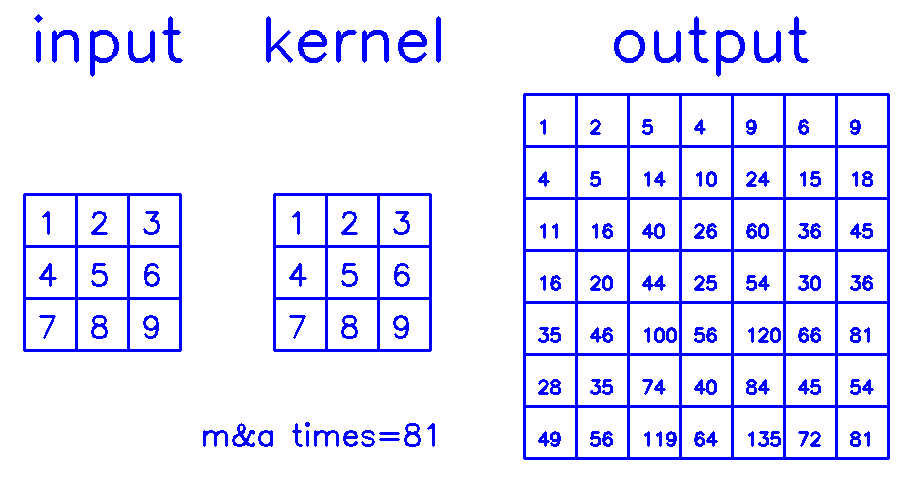
- 从output的角度来看,stride=2,padding=0
尤其是在stride>1的情况下,第二种的计算量是远小于第一种的,因为第一种有大量的无效0计算。
stride=2,padding=1
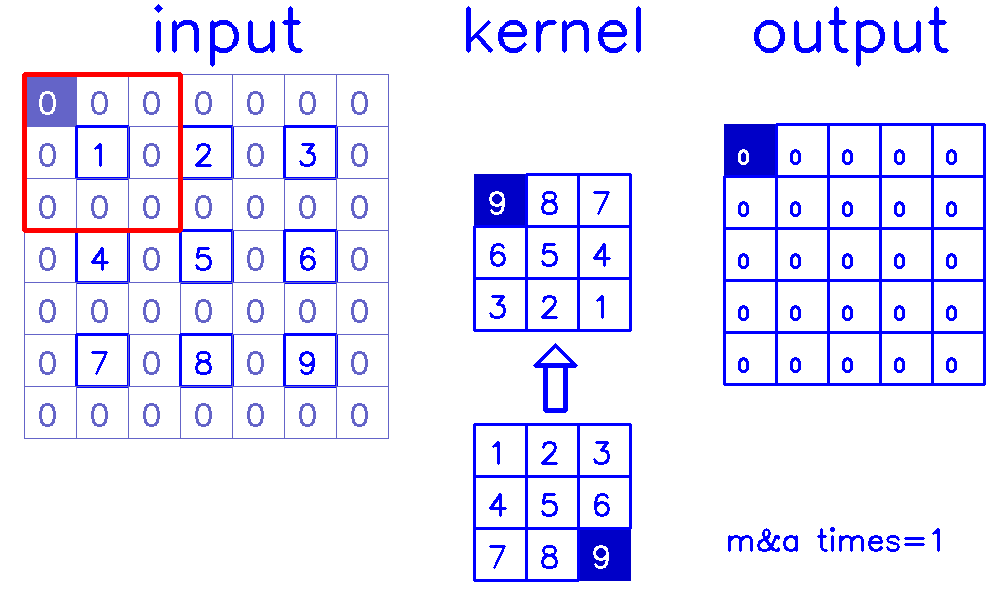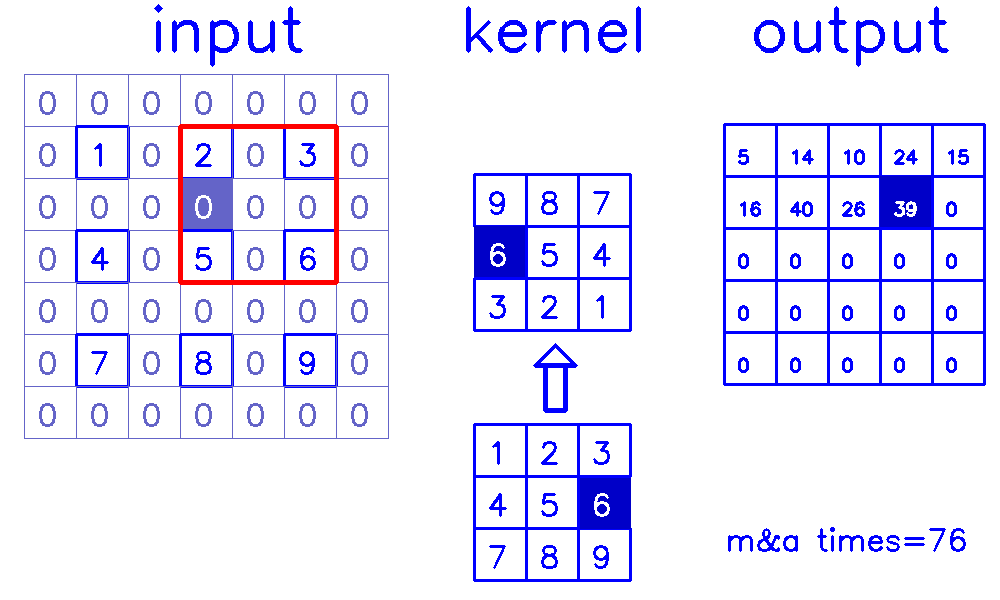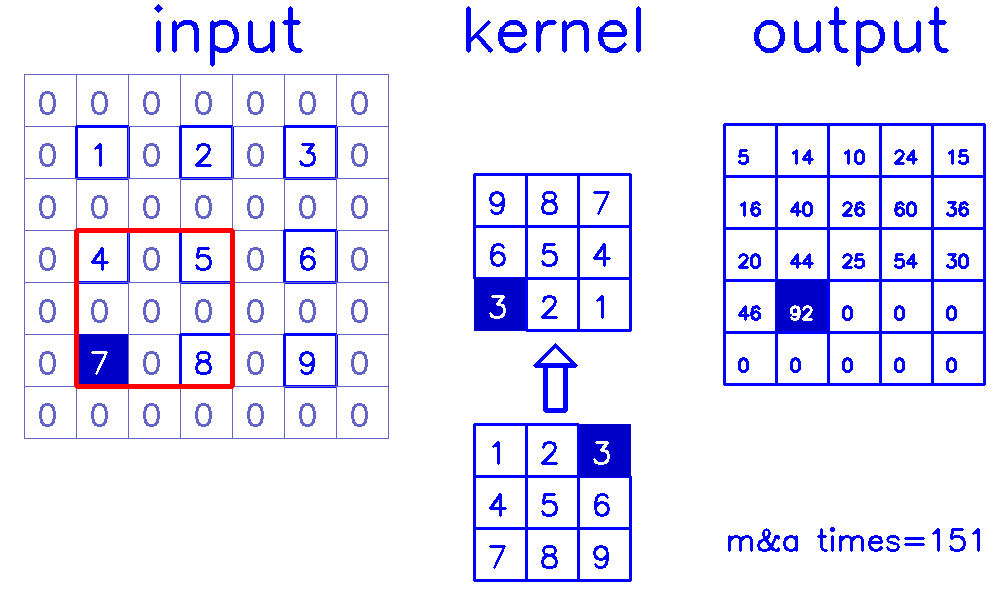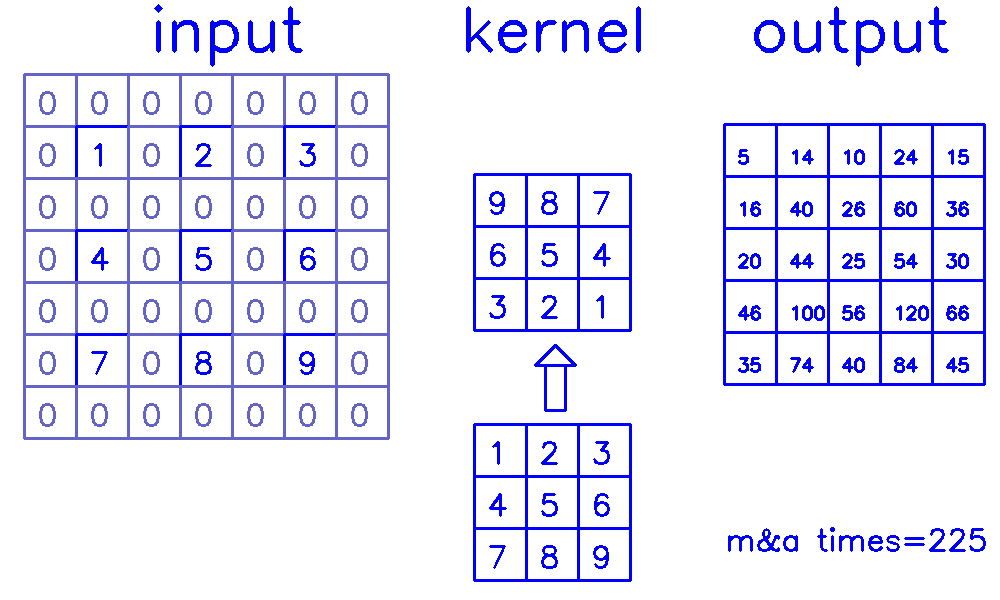
- 从input的角度来看,插入
(s-1)的0,做(k-p-1)的padding。在这个例子中,s=2,需插入1个0,然后进行(k-p-1)=(3-1-1)=1的padding。
output的角度看整个计算过程:
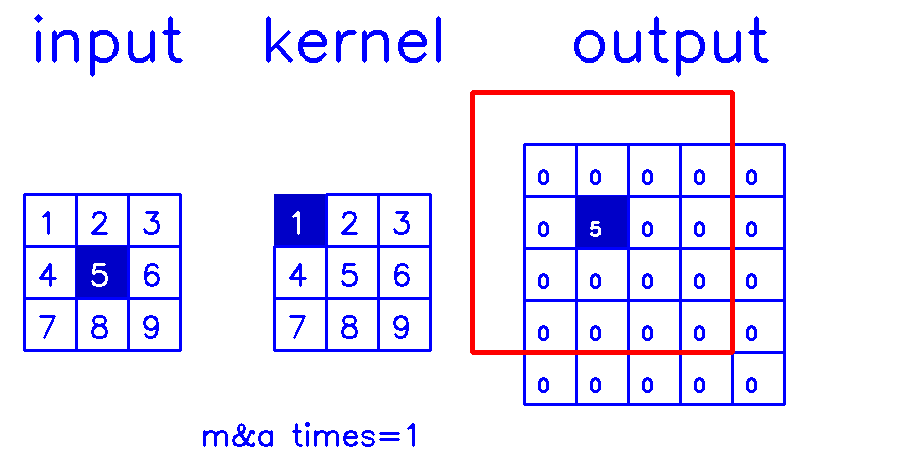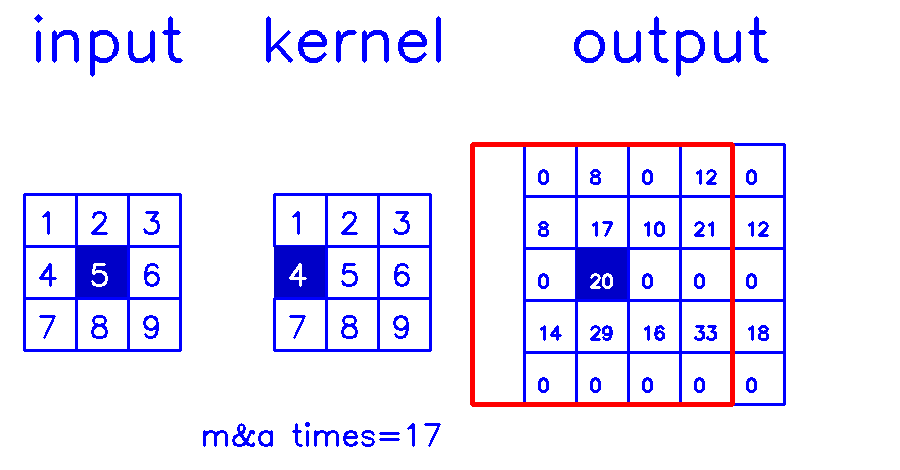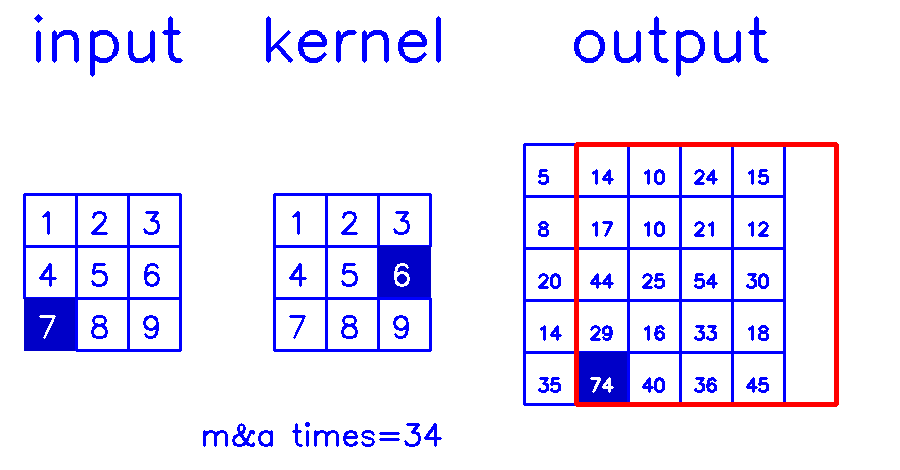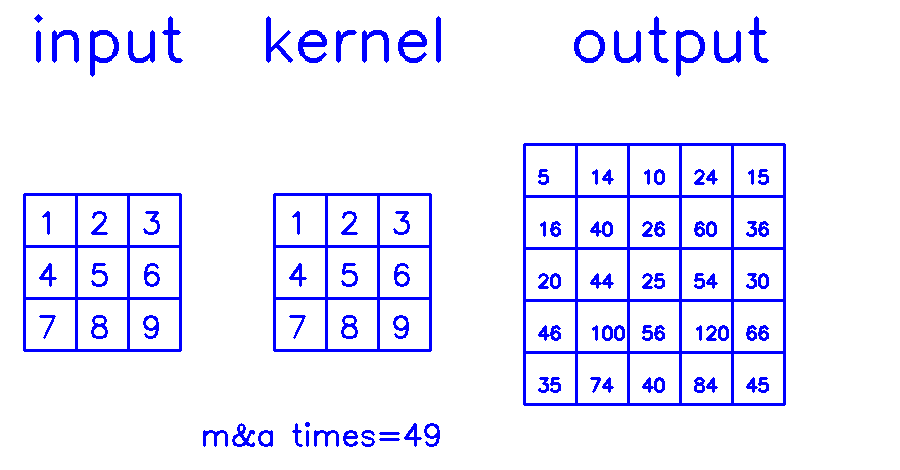
- 从output的角度来看,stride=2,padding=1
至此,各种情况展示的差不多了,转置卷积的padding和stride的含义,相信你也理解了。大家还是习惯用卷积那套参数来定义转置卷积,甚至在很多推理框架中,转置卷积这个算子的input指的是计算结果,output指的是输入(这又是另一个曾让我困扰的地方了hhh)。
转置卷积的加速 🚀
以最简单的stride=1,pad=0的情况为例:
直接计算方式
直接计算方式通过padding和补0操作,将 input 的 feature map 增大,导致整体计算量大幅度增大
其中有大量的0计算,其实是无效的。
相应的伪代码为:

优化计算方式
也就是第三章节中提到的,从output的角度来看的计算方式,这种优化方式避免了大量的无效0计算,其实是已经大大减小乘加计算量的。因此可以从这个角度做加速,效果很明显的。
从output的角度反过来寻找对应的input进行浮点乘加计算,这样便可以避免掉无效的0计算。
然而,在这6层for循环中,有大量的边界判断,这些if操作会严重影响计算并行度
相应的伪代码为:

进一步优化计算方式
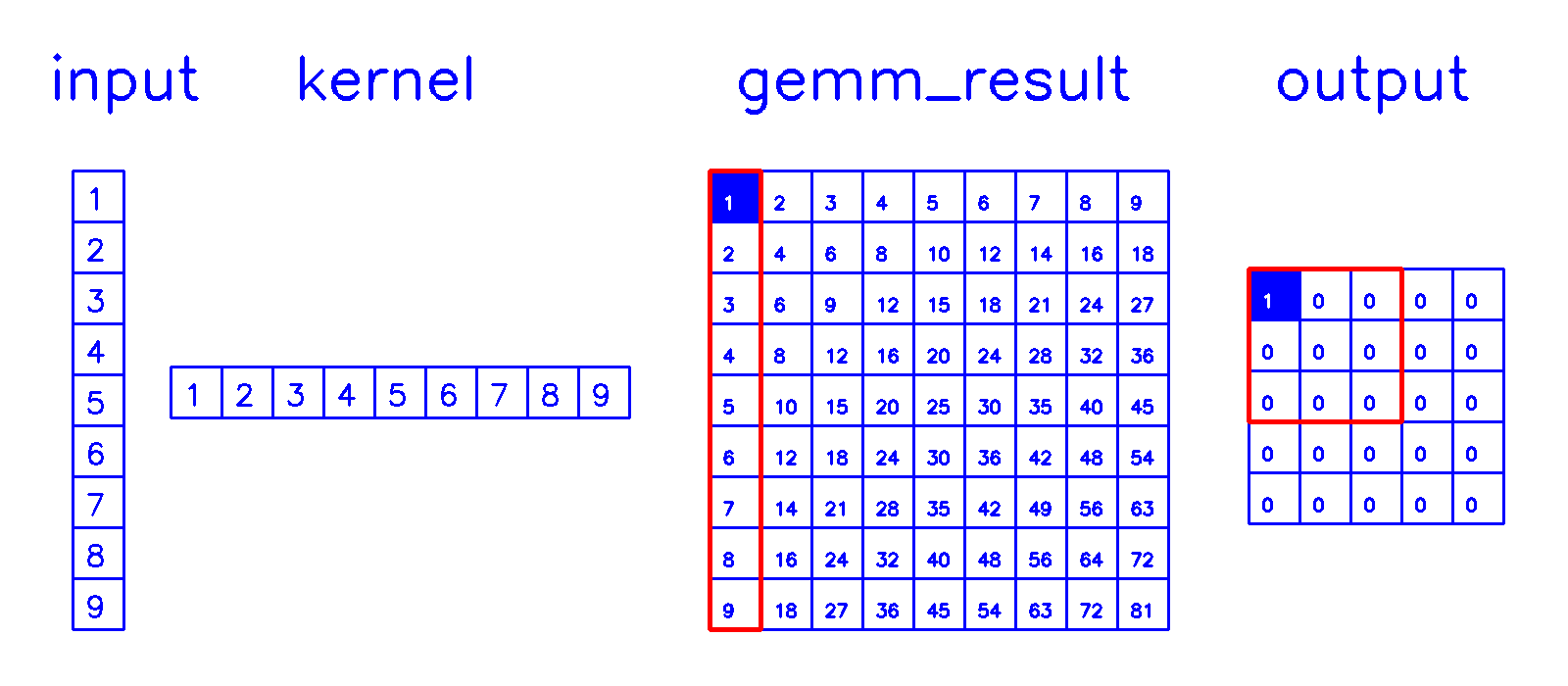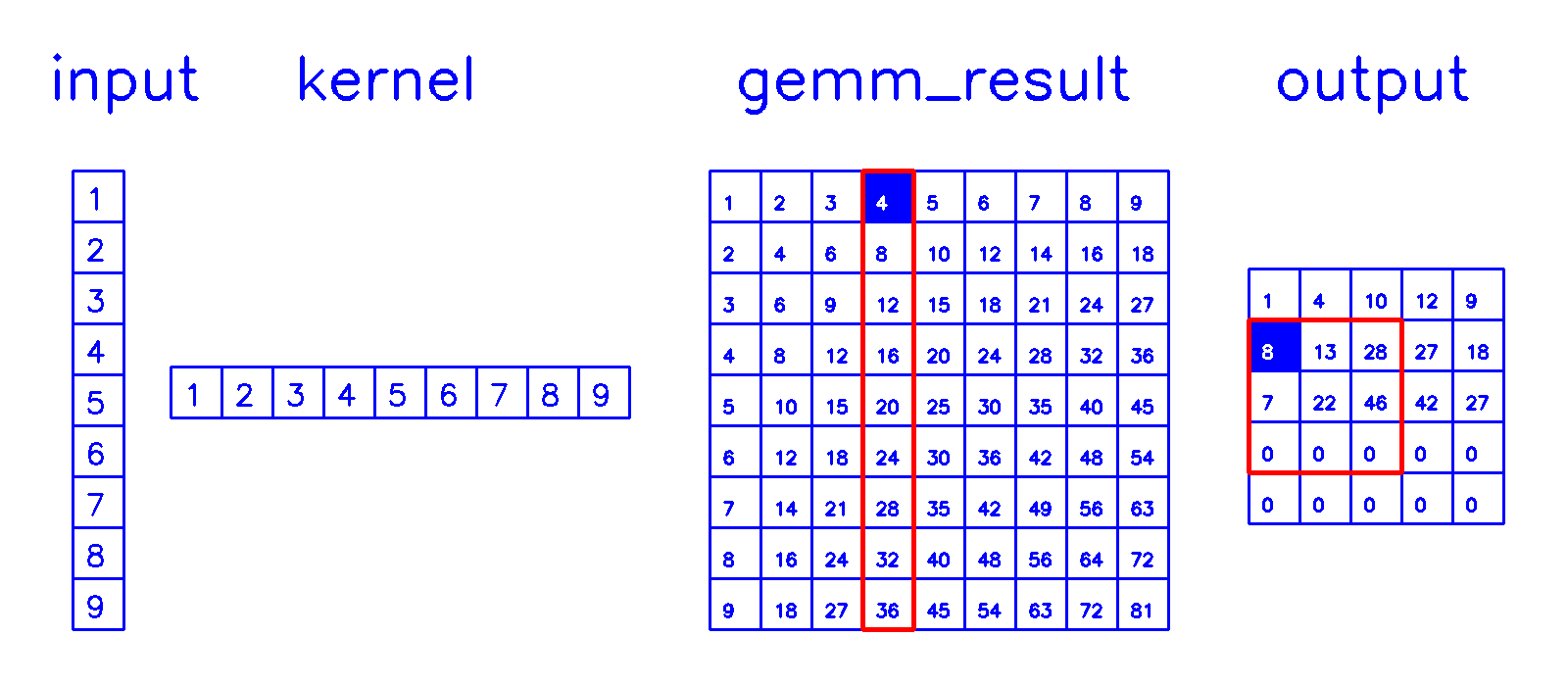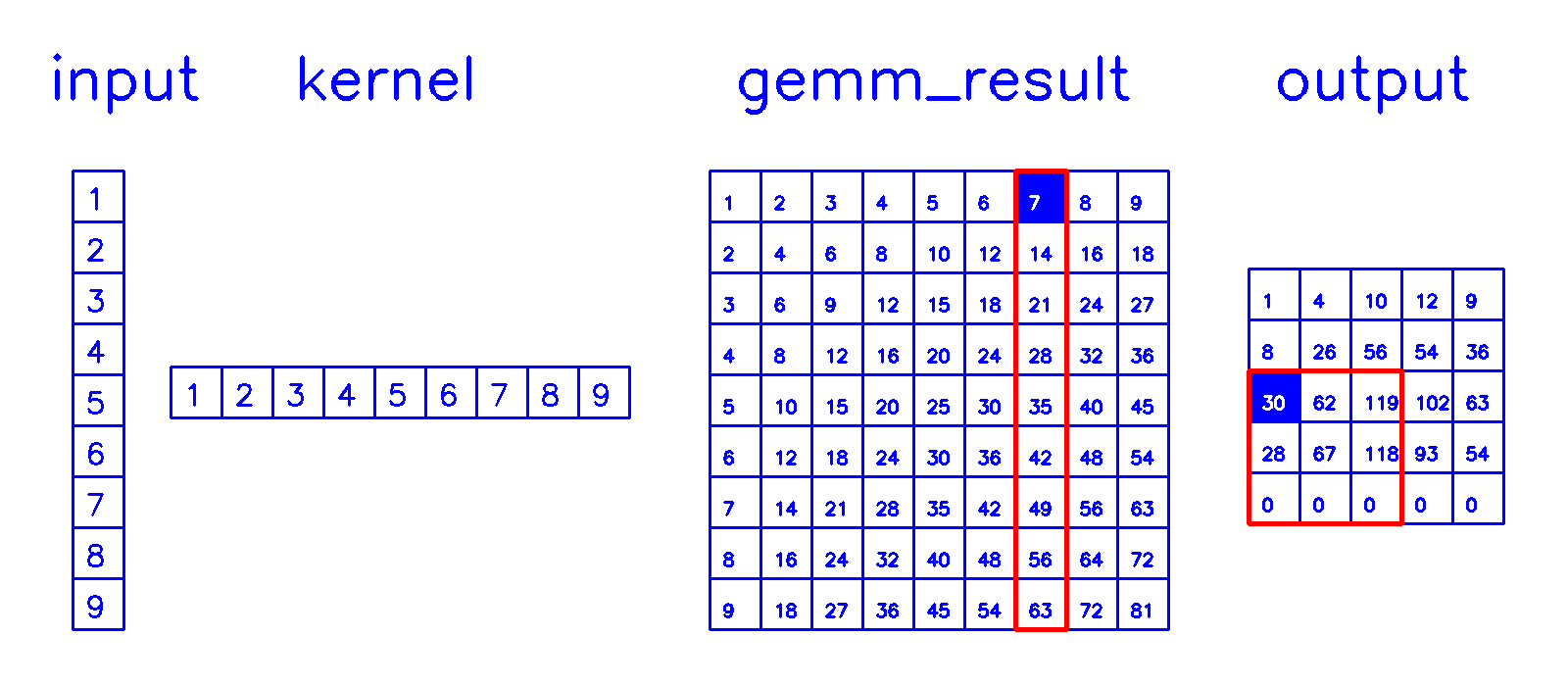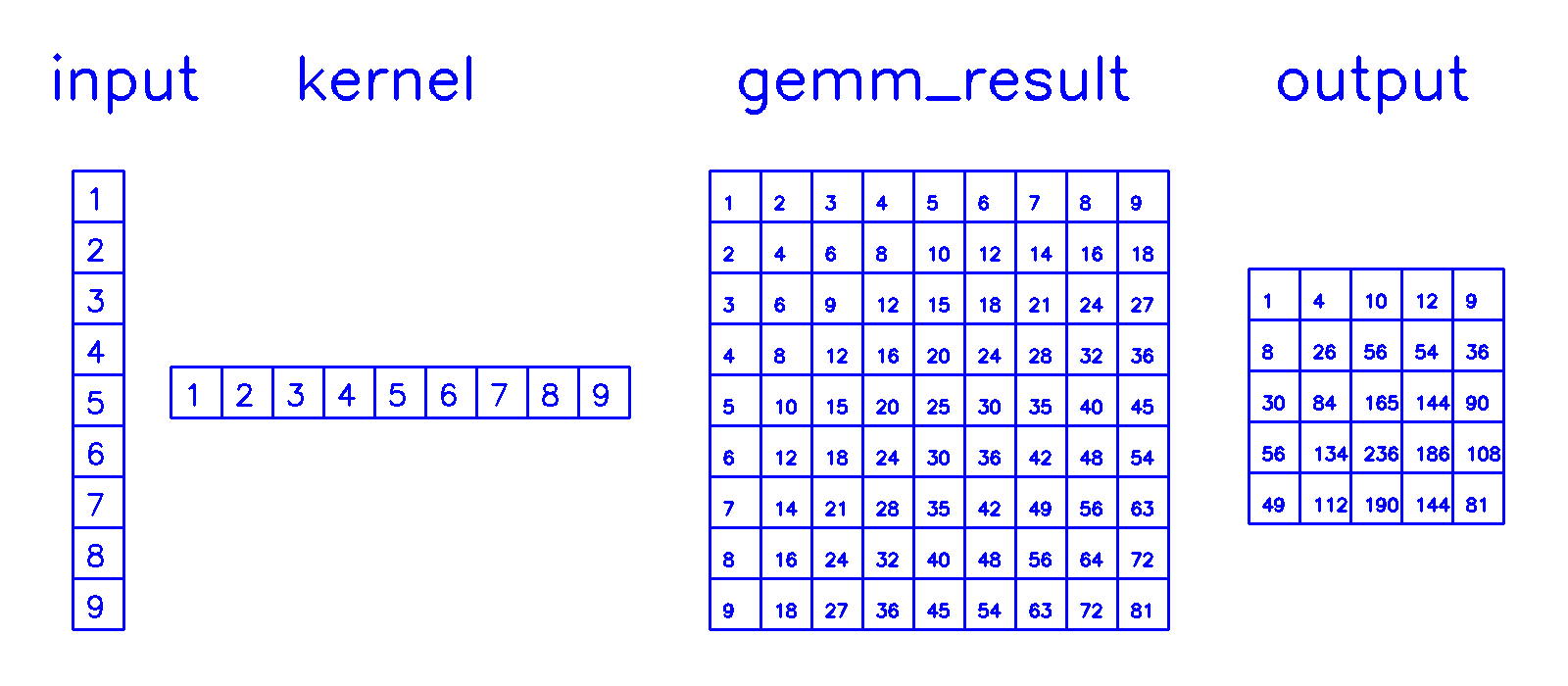
gemm计算
- 相当于做了6层for循环中的所有浮点乘法计算,该部分密集型的计算可以使用并行计算进行大幅加速
col2im计算
- 通过stride和padding计算累加规则,累加后还原出转置卷积的计算结果。
col2im 相应的伪代码为:

总结
转置卷积在诸如图像超分辨率、语音降噪等任务中还是很常见的,经过这一番的探索,现在也算是彻底理解转置卷积了。
关于转置卷积的加速,终极优化版本将转置卷积转换为
gemm+col2im,首先就是避免了大量的无效0计算,计算量通常可以减少为原来的18%~36%左右。
这样的坏处就是要开辟一块额外的内存用于存放gemm结果;好处就很明显了,将乘法和加法分离,对密集的乘法进行并行加速处理,无需边界判断,计算效率大大提升。其实精髓在于可以利用gemm的加速,如果再配合一块高速内存,转置卷积的计算速度提升个300%以上简直是轻轻松松啊。
参考文档
tf.keras.layers.Conv2DTranspose
What is Transposed Convolutional Layer?
Up-sampling with Transposed Convolution
图解转置卷积,我分别在conv_arithmetic和What is Transposed Convolutional Layer里看到,感觉后者更容易理解。
本文用图参考了aqeelanwar的代码,非常感谢。
图像压缩用了iloveimg,非常好用~


