前几天 openai 隆重推出 gpt-oss,模型的 MoE 部分采用了 MXFP4 格式让人震惊,这大大减少了对内存的依赖。
在RTX4090上做加速
RTX4090有一个很奇特的特性,使用 fp16 accum 的 matmul 的吞吐量是使用 fp32 accum 的 matmul 的两倍。
这是非常诱人的加速!
FlashMLA 实践
之前在 FlashMLA 源码分析 分析了 FlashMLA 的源码,后来我又实践了一下,在此记录一下进一步的学习成果。
FlashMLA 源码分析
今天Deepseek开源 FlashMLA,之前看过一些 MLA 相关知识了,感觉这是一个很好的学习 Cuda 加速的机会,于是实践学习记录一下。
Efficient Streaming Language Models with Attention Sinks
Deploy LLMs for infinite-length inputs without sacrificing efficiency and performance.
Optimize sgemm on RISC-V platform
This project records the process of optimizing SGEMM (single-precision floating point General Matrix Multiplication) on the riscv platform.
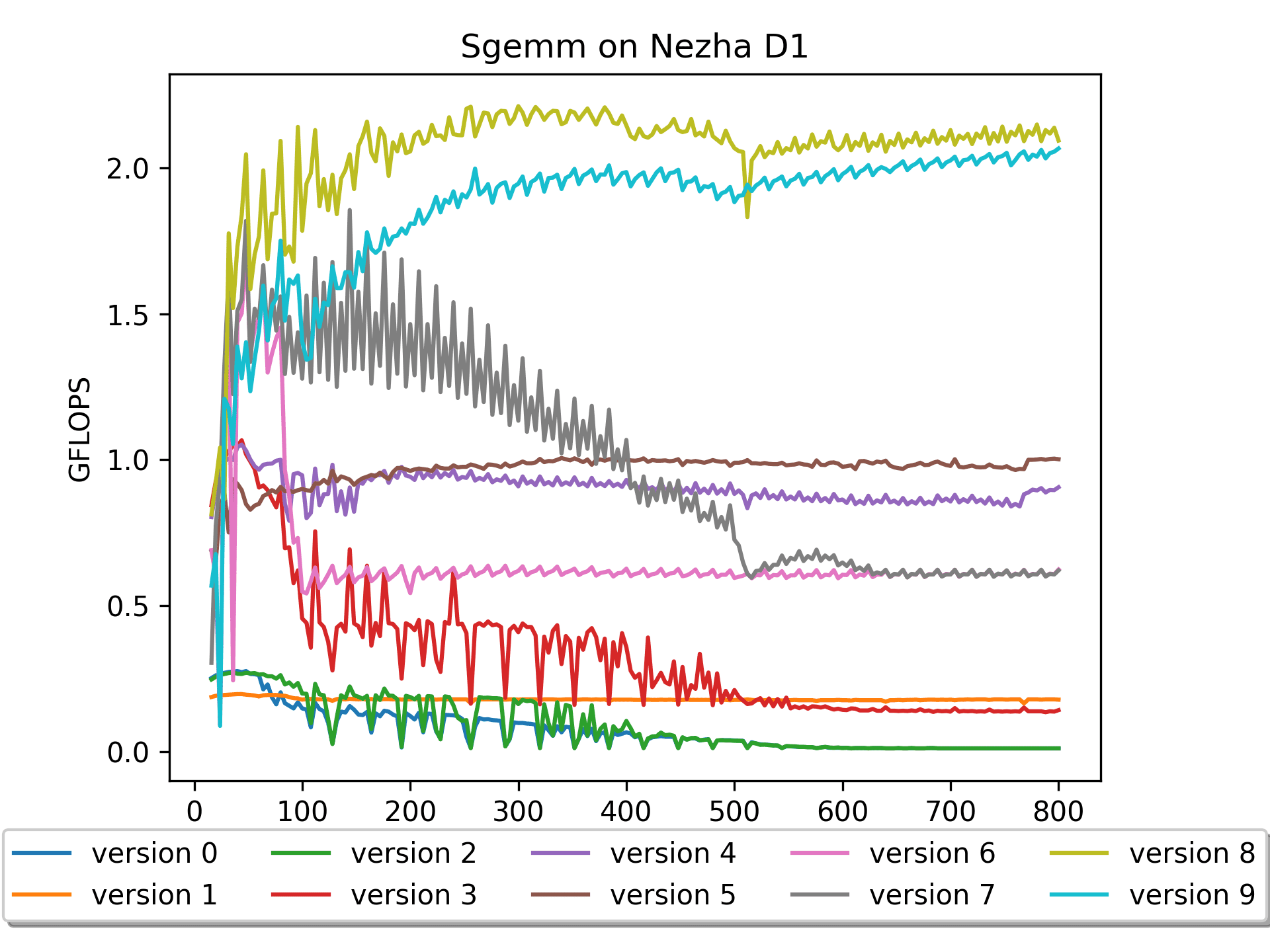
在riscv平台优化SGEMM
本项目记录了在riscv平台上优化SGEMM(单精度浮点通用矩阵乘法)的过程。
WeightonlyGEMM:dequantize_s4_to_fp16x2代码解析
本文聚焦于AWQ的W4A16 (4-bit weight, 16-bit activation) CUDA kernel的反量化。
Battlegrounds
Set up a flag: the completion progress reaches 100%
Now at 99%
Homogeneous_ShangHai
0、背景
0.0 前年(2021)
我在北京的校园里,设计并制作了一个六重竹笋,《六重蓝笋成长记(上)》和《六重蓝笋成长记(下)》,开始体会到竹笋的乐趣,并立志于做更高重的笋。
0.1 去年(2022)
我在上海的某个特殊时期,闲得实在是无聊,制作了 视频:从入门到夺笋,以缓解不能出去玩的郁闷,并立志于做更高重的七重(七色彩虹)竹笋。